This vignette demonstrates susieR in the context of
genetic fine-mapping. We use simulated data of expression level of a
gene (y) in N
\approx 600 individuals. We want to identify with the genotype
matrix X_{N\times P} (P=1001) the genetic variables that causes
changes in expression level.
The simulated data set is simulated to have exactly 3 non-zero effects.
The data-set
The loaded dataset contains regression data X and y, along with some other relevant properties in the context of genetic studies. It also contains the “true” regression coefficent the data is simulated from.
Notice that we’ve simulated 2 sets of Y as 2 simulation replicates. Here we’ll focus on the first data-set.
dim(Y)
# [1] 574 2Here are the 3 “true” signals in the first data-set:
b <- true_coef[,1]
plot(b, pch=16, ylab='effect size')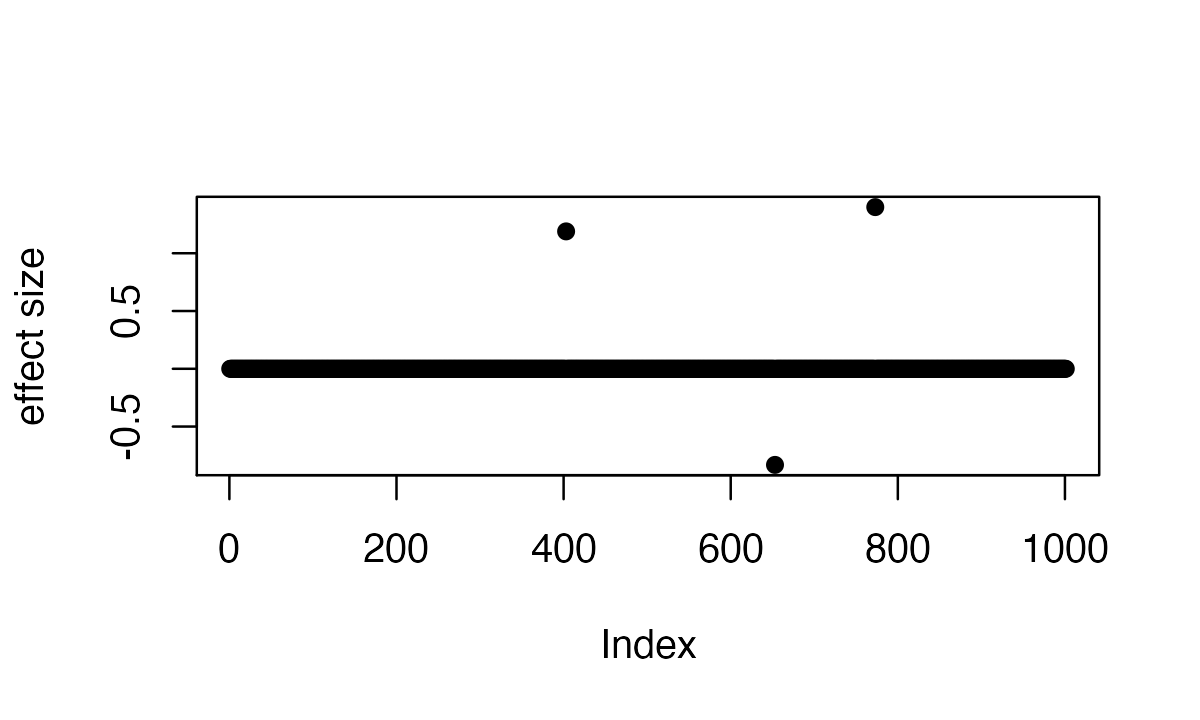
which(b != 0)
# [1] 403 653 773So the underlying causal variables are 403, 653 and 773.
Simple regression summary statistics
univariate_regression function can be used to compute
summary statistics by fitting univariate simple regression variable by
variable. The results are \hat{\beta}
and SE(\hat{\beta}) from which z-scores
can be derived. Again we focus only on results from the first
data-set:
sumstats <- univariate_regression(X, Y[,1])
z_scores <- sumstats$betahat / sumstats$sebetahat
susie_plot(z_scores, y = "z", b=b)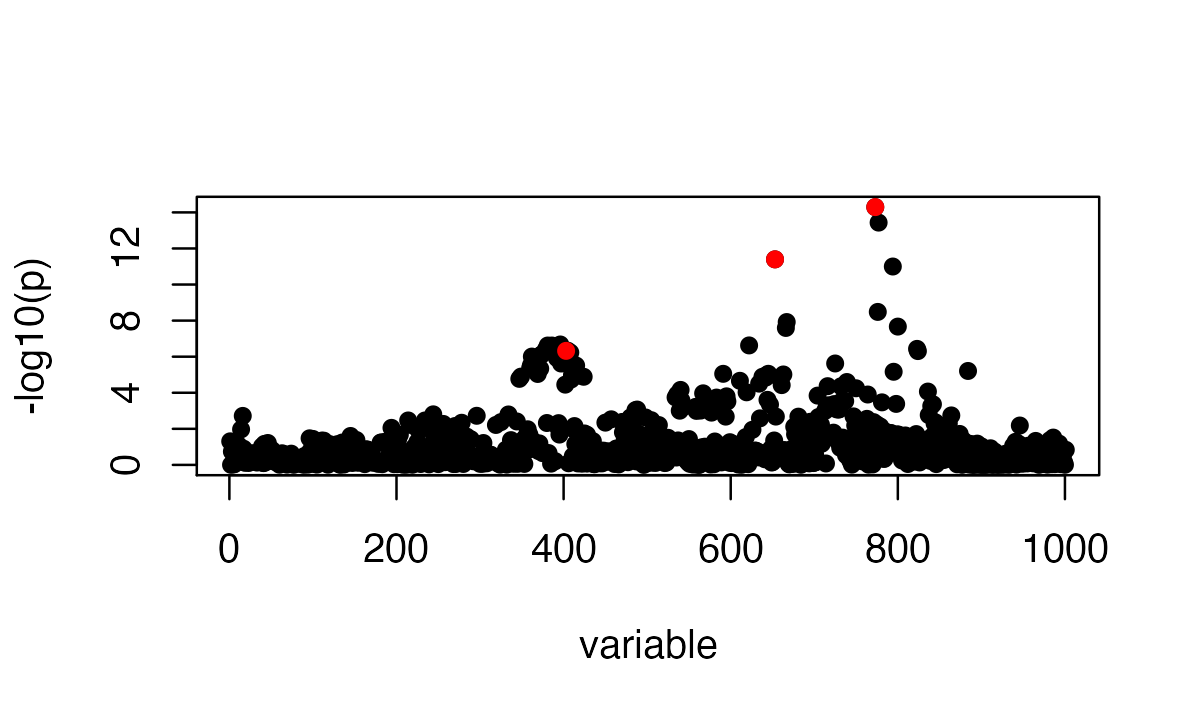
Fine-mapping with susieR
For starters, we assume there are at most 10 causal variables, i.e.,
set L = 10, although SuSiE is robust to the choice of
L.
The susieR function call is:
fitted <- susie(X, Y[,1],
L = 10,
verbose = TRUE)
# iter ELBO delta sigma2 mem V
# 1 -1380.5753 - 7.8424 0.16 GB [7.36e-01, 3.21e-01, 8.76e-03, 5.58e-03, 3.77e-03, 2.63e-03, 1.88e-03, 1.36e-03, 9.91e-04, 7.28e-04]
# 2 -1375.8576 4.72e+00 6.7474 0.16 GB [6.54e-01, 3.43e-01, 1.08e-01, 0 x 7]
# 3 -1370.3393 5.52e+00 6.6237 0.16 GB [5.96e-01, 3.92e-01, 2.95e-01, 0 x 7]
# 4 -1370.1090 2.30e-01 6.4170 0.16 GB [5.33e-01, 4.03e-01, 2.98e-01, 0 x 7]
# 5 -1370.1089 1.79e-04 6.4147 0.16 GB [5.31e-01, 4.03e-01, 2.98e-01, 0 x 7]
# 6 -1370.1089 2.01e-07 6.4148 0.16 GB [5.31e-01, 4.03e-01, 2.98e-01, 0 x 7] convergedCredible sets
By default, we output 95% credible set:
print(fitted$sets)
# $cs
# $cs$L2
# [1] 653
#
# $cs$L1
# [1] 773 777
#
# $cs$L3
# [1] 362 365 372 373 374 379 381 383 384 386 387 388 389 391 392 396 397 398 399
# [20] 400 401 403 404 405 407 408 415
#
#
# $purity
# min.abs.corr mean.abs.corr median.abs.corr
# L2 1.0000000 1.0000000 1.0000000
# L1 0.9815726 0.9815726 0.9815726
# L3 0.8686309 0.9640176 0.9720711
#
# $cs_index
# [1] 2 1 3
#
# $coverage
# [1] 0.9998237 0.9988853 0.9539828
#
# $requested_coverage
# [1] 0.95The 3 causal signals have been captured by the 3 CS reported here.
The 3rd CS contains many variables, including the true causal variable
403. The minimum absolute correlation is 0.86.
If we use the default 90% coverage for credible sets, we still capture the 3 signals, but “purity” of the 3rd CS is now 0.91 and size of the CS is also a bit smaller.
sets <- susie_get_cs(fitted,
X = X,
coverage = 0.9,
min_abs_corr = 0.1)
print(sets)
# $cs
# $cs$L2
# [1] 653
#
# $cs$L1
# [1] 773 777
#
# $cs$L3
# [1] 373 374 379 381 383 384 386 387 388 389 391 392 396 398 399 400 401 403 404
# [20] 405 407 408
#
#
# $purity
# min.abs.corr mean.abs.corr median.abs.corr
# L2 1.0000000 1.0000000 1.0000000
# L1 0.9815726 0.9815726 0.9815726
# L3 0.9119572 0.9726283 0.9765888
#
# $cs_index
# [1] 2 1 3
#
# $coverage
# [1] 0.9998237 0.9988853 0.9119942
#
# $requested_coverage
# [1] 0.9Posterior inclusion probabilities
Previously we’ve determined that summing over 3 single effect regression models is approperate for our application. Here we summarize the variable selection results by posterior inclusion probability (PIP):
susie_plot(fitted, y="PIP", b=b)
The true causal variables are colored red. The 95% CS identified are circled in different colors. Of interest is the cluster around position 400. The true signal is 403 but apparently it does not have the highest PIP. To compare ranking of PIP and original z-score in that CS:
i <- fitted$sets$cs[[3]]
z3 <- cbind(i,z_scores[i],fitted$pip[i])
colnames(z3) <- c('position', 'z-score', 'PIP')
z3[order(z3[,2], decreasing = TRUE),]
# position z-score PIP
# [1,] 396 5.189811 0.056705424
# [2,] 381 5.164794 0.100361653
# [3,] 386 5.164794 0.100361653
# [4,] 379 5.077563 0.054180594
# [5,] 391 5.068388 0.055952914
# [6,] 383 5.057053 0.052897198
# [7,] 384 5.057053 0.052897198
# [8,] 389 5.052519 0.042161613
# [9,] 405 5.039617 0.045761860
# [10,] 403 5.035949 0.031993357
# [11,] 387 5.013526 0.041042157
# [12,] 388 4.997955 0.039650624
# [13,] 408 4.994865 0.041550248
# [14,] 404 4.954407 0.032013095
# [15,] 374 4.948060 0.030571403
# [16,] 373 4.934410 0.023577387
# [17,] 362 4.894243 0.012145565
# [18,] 399 4.860780 0.026453261
# [19,] 392 4.856384 0.019740961
# [20,] 407 4.849285 0.014698666
# [21,] 400 4.827361 0.021658789
# [22,] 365 4.782770 0.006263458
# [23,] 398 4.751205 0.012907415
# [24,] 401 4.723184 0.014857110
# [25,] 397 4.716886 0.008690756
# [26,] 415 4.663208 0.009002747
# [27,] 372 4.581560 0.005886095Choice of priors
Notice that by default SuSiE estimates prior effect size from data.
For fine-mapping applications, however, we sometimes have knowledge of
SuSiE prior effect size since it is parameterized as percentage of
variance explained (PVE) by a non-zero effect, which, in the context of
fine-mapping, is related to per-SNP heritability. It is possible to use
scaled_prior_variance to specify this PVE and explicitly
set estimate_prior_variance=FALSE to fix the prior effect
to given value.
In this data-set, SuSiE is robust to choice of priors. Here we set PVE to 0.2, and compare with previous results:
fitted = susie(X, Y[,1],
L = 10,
estimate_residual_variance = TRUE,
estimate_prior_variance = FALSE,
scaled_prior_variance = 0.2)
susie_plot(fitted, y='PIP', b=b)
which largely remains unchanged.
A note on covariate adjustment
To include covariate Z in SuSiE, one approach is to
regress it out from both y and X, and then run
SuSiE on the residuals. The code below illustrates the procedure:
remove.covariate.effects <- function (X, Z, y) {
# include the intercept term
if (any(Z[,1]!=1)) Z = cbind(1, Z)
A <- forceSymmetric(crossprod(Z))
SZy <- as.vector(solve(A,c(y %*% Z)))
SZX <- as.matrix(solve(A,t(Z) %*% X))
y <- y - c(Z %*% SZy)
X <- X - Z %*% SZX
return(list(X = X,y = y,SZy = SZy,SZX = SZX))
}
out = remove.covariate.effects(X, Z, Y[,1])
fitted_adjusted = susie(out$X, out$y, L = 10)Note that the covariates Z should have a column of ones
as the first column. If not, the above function
remove.covariate.effects will add such a column to
Z before regressing it out. Data will be centered as a
result. Also the scale of data is changed after regressing out
Z. This introduces some subtleties in terms of interpreting
the results. For this reason, we provide covariate adjustment procedure
as a tip in the documentation and not part of
susieR::susie() function. Cautions should be taken when
applying this procedure and interpreting the result from it.
Sufficient statistics: compute_suff_stat and
susie_ss
When individual-level data (X, y)
are available and the sample size N is
much larger than the number of variables P, calling susie(X, y) directly
is wasteful: each IBSS iteration touches X again, and when
many response vectors are fit against the same X (for
example, many proteins or genes on a shared locus), X'X is rebuilt every time. The sufficient
statistics (X'X, X'y, y'y,
n) capture everything susie needs; once they are
computed, susie_ss can be called directly and X'X reused across response vectors.
The function compute_suff_stat produces these sufficient
statistics from (X, y):
ss <- compute_suff_stat(X, Y[,1])
str(ss)
# List of 6
# $ XtX : num [1:1001, 1:1001] 11.75 -6.31 -9.06 3.37 -1.97 ...
# $ Xty : num [1:1001] 18.819 0.589 -61.164 19.976 2.527 ...
# $ yty : num 4494
# $ n : int 574
# $ y_mean : num 1.19e-16
# $ X_colmeans: num [1:1001] -2.73e-18 3.87e-19 -1.72e-17 -1.52e-18 1.32e-17 ...They pass directly to susie_ss:
fitted_ss <- susie_ss(XtX = ss$XtX, Xty = ss$Xty, yty = ss$yty, n = ss$n,
X_colmeans = ss$X_colmeans, y_mean = ss$y_mean,
L = 10, estimate_residual_variance = TRUE)With matched hyperparameters, susie_ss(...) is
numerically equivalent to running susie on (X, y) directly:
For a second response vector on the same X, only
Xty and yty need to be recomputed; the costly
X'X is reused:
y2_centered <- Y[,2] - mean(Y[,2])
ss2 <- ss
ss2$Xty <- drop(y2_centered %*% X)
ss2$yty <- sum(y2_centered^2)
ss2$y_mean <- mean(Y[,2])
fitted_ss2 <- susie_ss(XtX = ss2$XtX, Xty = ss2$Xty, yty = ss2$yty,
n = ss2$n, X_colmeans = ss2$X_colmeans,
y_mean = ss2$y_mean, L = 10)susie() emits a hint suggesting this workflow whenever
nrow(X) >= 2 * ncol(X).
Session information
Here are some details about the computing environment, including the versions of R, and the R packages, used to generate these results.
sessionInfo()
# R version 4.4.3 (2025-02-28)
# Platform: x86_64-conda-linux-gnu
# Running under: Ubuntu 24.04.4 LTS
#
# Matrix products: default
# BLAS/LAPACK: /home/runner/work/susieR/susieR/.pixi/envs/r44/lib/libopenblasp-r0.3.33.so; LAPACK version 3.12.0
#
# locale:
# [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
# [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
# [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
# [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
#
# time zone: Etc/UTC
# tzcode source: system (glibc)
#
# attached base packages:
# [1] stats graphics grDevices utils datasets methods base
#
# other attached packages:
# [1] susieR_0.16.6
#
# loaded via a namespace (and not attached):
# [1] Matrix_1.7-5 gtable_0.3.6 jsonlite_2.0.0
# [4] compiler_4.4.3 crayon_1.5.3 Rcpp_1.1.2
# [7] jquerylib_0.1.4 systemfonts_1.3.2 scales_1.4.0
# [10] textshaping_1.0.5 yaml_2.3.12 fastmap_1.2.0
# [13] lattice_0.22-9 plyr_1.8.9 ggplot2_4.0.3
# [16] R6_2.6.1 mixsqp_0.3-54 knitr_1.51
# [19] htmlwidgets_1.6.4 desc_1.4.3 zigg_0.0.2
# [22] bslib_0.11.0 RColorBrewer_1.1-3 rlang_1.3.0
# [25] reshape_0.8.10 cachem_1.1.0 xfun_0.60
# [28] fs_2.1.0 sass_0.4.10 S7_0.2.2
# [31] RcppParallel_5.1.11-2 otel_0.2.0 cli_3.6.6
# [34] pkgdown_2.2.1 digest_0.6.39 grid_4.4.3
# [37] irlba_2.3.7 lifecycle_1.0.5 vctrs_0.7.3
# [40] Rfast_2.1.5.2 evaluate_1.0.5 glue_1.8.1
# [43] farver_2.1.2 ragg_1.5.2 rmarkdown_2.31
# [46] matrixStats_1.5.0 tools_4.4.3 htmltools_0.5.9