Introduction to Dynamical Statistical Comparisons
In this tutorial, you will get acquainted with the basic features of DSC through a simple example. This tutorial only explains the basic features at a high level. If you prefer to begin with a more precise (and more technical) overview of DSC concepts, see DSC Basics, Part I.
All the modules in this example are implemented in R. Being familiar with R is certainly helpful, but not essential, as the R code used in the example is not complicated. DSC currently supports two programming languages: R and Python.
This is a working example—optionally, you may install DSC, and try running this example DSC program as you read through the tutorial. For more details, consult the README in the “one sample location” DSC vignette.
An illustration: the simulate-analyze-score design pattern
We begin by considering a special case of DSC.
Suppose we want to compare several methods for a particular inference task, denoted by $I$. For example, $I$ could be:
-
Predict the missing entries of a matrix;
-
Estimate a covariance matrix from a data sample;
-
Estimate a regression function relating outcome $Y$ to covariates (features) $X$.
For these three tasks, and others, we could conduct a benchmarking experiment to compare methods to perform $I$ by repeating the following three steps:
-
Simulate some data suitable for performing $I$.
-
Analyze the data with a method designed to perform $I$.
-
Score how well the method performed $I$ (e.g., by comparing the methods’ estimates against the ground-truth provided by the simulation).
We call this basic structure the “simulate-analyze-score” design pattern. This is only one example of what DSC can handle—it can also handle much more complex settings than this—but this basic structure suffices to explain some of the key concepts.
The DSC building blocks: modules, groups and pipelines
Typically we will want to try different ways of implementating steps 1–3; that is, different ways to simulate the data, different ways to analyze the data, and different ways to score how well a method performed.
In DSC, each different way of implementing a step is expressed as a “module”. A “group of modules” defines the collection of alternative implementations of a step.
In our example, we define:
-
A group of
simulatemodules, each of which can perform step 1; -
A group of
analyzemodules, each of which can perform step 2; and -
A group of
scoremodules, each of which can perform step 3.
Running the benchmark then consists of running sequences of modules—called “pipelines” in DSC—and each pipeline invokes one module from the simulate group, followed by a module from the analyze group, then a module from the score group.
DSC provides a flexible and easy-to-use language to manage and run benchmarks like these, as well as more complex ones. The modular design of DSC makes it easy to extend benchmarks (e.g., by defining a new analyze module)—hence the Dynamic in Dynamic Statistical Comparisons.
Also, DSC efficiently uses the available computational resources by running modules in parallel when possible; for example, once a simulate module has created a dataset, DSC may run multiple analyze modules in parallel.
Running a DSC benchmark
There are three essential ingredients to a DSC benchmark:
-
A “DSC file”, which defines the modules, groups and pipelines, and how information flows from one module to another. The DSC file is a text file written in DSC syntax, as we show below (this syntax is explained in more detail in DSC Basics, Part I).
-
A call to the
dsccommand-line program. This runs all pipelines defined by the DSC file, and saves the results to files in a structured way that makes them easy to query. -
Query and summarize the results. We provide two querying interfaces. In this tutorial, we will demonstrate the R interface, which provides a convenient way of reading the DSC results into a data frame in R. We also provide a command-line tool,
dsc-query, which is demonstrated in other tutorials.
Example
We now illustrate how DSC can be used to implement a simple benchmark.
In this example, we have a simple task: estimate the mean of a population given a random sample from the population.
We compare two methods for estimating the population mean: the sample mean and the sample median.
We simulate under two different population distributions: a t distribution and a normal distribution.
And we compute accuracy of the estimates using two different metrics: squared error, and absolute error.
The DSC file
We implement this DSC in R. Material used, including the DSC file, can be found in the “one sample location” DSC vignette.
All source code needed to define the DSC is given in a single text file, first_investigation.dsc. Here, we give only a high-level overview of the code, deferring an explanation of the syntax to DSC Basics, Part I and DSC Basics, Part II. For now, don’t worry about understanding the actual code—the code is only shown here to illustrate what DSC code looks like.
# Simulate samples from the normal distribution with mean 0 and
# standard deviation 1.
normal: R(x <- rnorm(n,mean = mu,sd = 1))
mu: 0
n: 100
$data: x
$true_mean: mu
# Simulate samples from the non-centered t-distribution with 2 degrees
# of freedom.
t: R(x <- mu + rt(n,df = 2))
mu: 3
n: 100
$data: x
$true_mean: mu
# Estimate the population mean by computing the mean value of the
# provided sample.
mean: R(y <- mean(x))
x: $data
$est_mean: y
# Estimate the population mean by computing the median value of the
# provided sample.
median: R(y <- median(x))
x: $data
$est_mean: y
# Compute the error in the estimated mean by taking the squared
# difference between the true mean and the estimated mean.
sq_err: R(e <- (x - y)^2)
x: $est_mean
y: $true_mean
$error: e
# Compute the error in the estimated mean by taking the absolute
# difference between the true mean and the estimated mean.
abs_err: R(e <- abs(x - y))
x: $est_mean
y: $true_mean
$error: e
DSC:
define:
simulate: normal, t
analyze: mean, median
score: abs_err, sq_err
run: simulate * analyze * score
This DSC file defines six modules:
-
two
simulatemodules (normalandt), -
two
analyzemodules (meanandmedian), and -
two
scoremodules (sq_errandabs_err).
Each module in this example involves only one line of R code (for more complex modules, the code can live in separate files).
The DSC file then defines the module groups (simulate, analyze and score) and the pipelines to run; simulate * analyze * score indicates that all sequences of the simulate, analyze and score modules should be run.
Run DSC
To run DSC, we first change the working directory to the location of the first_investigation.dsc file. (Here we assume the dsc repository is stored in the git subdirectory of your home directory. If you are running the example yourself, please move to the appropriate directory on your computer.)
cd ~/git/dsc/vignettes/one_sample_location
If there are any previously generated results, let’s remove them before moving on.
rm -Rf first_investigation.html first_investigation.log first_investigation
Before executing the benchmark, we can use the dsc command-line program to get a summary of what this benchmark includes:
dsc first_investigation.dsc -h
INFO: MODULES
+------------------------------------------------------------------+
| Group [simulate] |
| | - parameters - | - input - | - output - | - type - |
| normal | mu, n | | data, true_mean | R |
| t | mu, n | | data, true_mean | R |
+-------------------------------------------------------------+
| Group [analyze] |
| | - parameters - | - input - | - output - | - type - |
| mean | | data | est_mean | R |
| median | | data | est_mean | R |
+------------------------------------------------------------------------+
| Group [score] |
| | - parameters - | - input - | - output - | - type - |
| abs_err | | est_mean, true_mean | error | R |
| sq_err | | est_mean, true_mean | error | R |
INFO: PIPELINES
1: simulate -> analyze -> score
INFO: PIPELINES EXPANDED
1: normal * mean * abs_err
2: normal * mean * sq_err
3: normal * median * abs_err
4: normal * median * sq_err
5: t * mean * abs_err
6: t * mean * sq_err
7: t * median * abs_err
8: t * median * sq_err
Now we run 10 replicates of this benchmark (each replicate uses a different sequence of pseudorandom numbers to simulate the data), with 2 threads:
dsc first_investigation.dsc --replicate 10 -c 2
INFO: DSC script exported to first_investigation.html
INFO: Constructing DSC from first_investigation.dsc ...
INFO: Building execution graph & running DSC ...
[#############################] 29 steps processed (155 jobs completed)
INFO: Building DSC database ...
INFO: DSC complete!
INFO: Elapsed time 30.451 seconds.
(For first time users of DSC, a companion R package dscrutils should automatically installed at this point.)
When run, DSC will create results files in the folder first_investigation (this is the default folder name, and it can be changed in the DSC file). Below, we will see how to query these results and read them into R.
In addition, DSC will create a webpage summarizing the results (in this example, it is first_investigation.html). This file allows you to conveniently browse the DSC file, the executed pipelines, and the corresponding source code.
Query the results
Next, we will read the results into R using the dscquery function from the dscrutils package. To do so, change the working directory in R to the location of the first_investigation.dsc file.
setwd("~/GIT/dsc/vignettes/one_sample_location")
Since this example is small, it is convenient to load all the results into an R data frame and explore the data frame interactively in the R environment. In more complex examples, one might want to start by extracting subsets of results using query conditions; type help(dscquery) in R for more information.
library(dscrutils)
dscout <- dscquery(dsc.outdir = "dsc_result",
targets = c("simulate","analyze","score.error"))
head(dscout)
Once the results are in an R data frame like this, we can easily use standard functions in R to investigate them further.
For example, we can generate an informative summary of the results using the aggregate function, followed by a call to the order function to arrange the rows so that it is easier to compare the mean and median estimates:
dscsummary <- aggregate(score.error ~ simulate + analyze + score,dscout,mean)
dscsummary[with(dscsummary,order(simulate,score)),]
In this small experiment with 10 replicates (most likely too small to draw any meaningful conclusions!), we see that the median is a more accurate estimate of the population mean for t-distributed data (on average), and it is also a better estimate for normally distributed data judging as measured by the absolute error—but it is not better if we look at the squared differences.
Visualize the results
Next, we demonstrate use of the ggplot2 package to create a visual summary the squared-error results:
# Load the ggplot2 package and set up graphics within the Jupyter environment.
library(ggplot2)
library(repr)
options(repr.plot.width = 3.5,repr.plot.height = 2.5)
# This function selects the DSC results with the squared-error metric only,
# removing unusually large errors, then creates a combined violin and dotplot
# summarizing the accuracy of the two analysis methods ("mean" and "median").
create.boxplot <- function (dat) {
pdat <- subset(dat,score == "sq_err" & score.error < 0.1)
return(qplot(x = simulate,y = score.error,data = pdat,color = analyze,geom = "boxplot",
xlab = "analysis method",ylab = "squared error",
main = "results from normal & t simulations"))
}
create.boxplot(dscout)
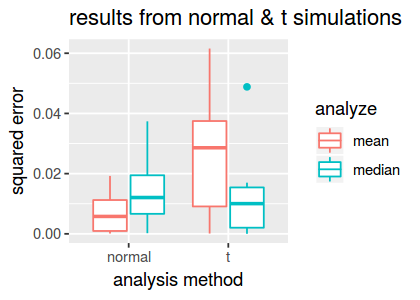
Based on the results from the 10 replicates, we see that the median is substantially more accurate than the mean in the t simulations, on average, and it yields only slightly worse accuracy in the normal simulations.
Expand the experiment
Above, we compared different ways to estimate the population mean from a sample, and examined the results of this comparison. We observed that the median estimate tends to be more accurate than the mean estimate. However, this observation was based on very few data—we only ran 10 replicates.
Here, we increase the number of replicates to 20.
We will see that DSC does this efficiently; it determines the minimum effort needed to produce the new results, and only runs scripts if they are needed to generate new results.
dsc first_investigation.dsc --replicate 20 -c 2
INFO: DSC script exported to first_investigation.html
INFO: Constructing DSC from first_investigation.dsc ...
INFO: Building execution graph & running DSC ...
[#############################] 29 steps processed (155 jobs completed, 140 jobs ignored)
INFO: Building DSC database ...
INFO: DSC complete!
INFO: Elapsed time 29.287 seconds.
From this summary, we see that 155 new jobs (including pipeline meta jobs and jobs executing module instances) are executed in this DSC run, and 140 module outputs are unchanged from the previous run, and therefore did not need to be generated again. Although the benefit is not particularly noticeable for this toy example, avoiding unnecessary computations can yield a huge payoff when running complex analyses or when working with very large data sets.
Let’s now load the results from our expanded DSC run.
dscout2 <- dscquery(dsc.outdir = "dsc_result",
targets = c("simulate","analyze","score.error"))
Comparing to the previous dscquery output, we confirm that the new DSC run generated twice as many results.
nrow(dscout)
nrow(dscout2)
Add a new method to the DSC benchmark
Another commonly used approach to estimate a population mean is the “Winsorized” estimator; this approach is more robust to unusually large and unusually small values because top and bottom value are trimmed. Here we use the Winsorized mean implemented in the psych package.
To compare the Winsorized mean against the regular mean and median estimates, we add the following lines to our DSC file:
# Estimate the population mean by computing the Winsorized mean; the
# mean is computed after trimming the top and bottom 10% quantiles.
winsor: R(y <- psych::winsor.mean(x,trim,na.rm = TRUE))
trim: 0.1
x: $data
$est_mean: y
This module is similar in structure to the mean and t modules; the main difference is the R code inside the R().
To include the Winsorized mean method in our benchmark, we also need to add the winsor module to the “analyze” module group:
DSC:
define:
simulate: normal, t
analyze: mean, median, winsor
score: abs_err, sq_err
run: simulate * analyze * score
output: first_investigation
Similar to adding new replicates, we will see that DSC does the minimum computation needed to augment the benchmark with the Winsorized mean method.
dsc add_winsor_method1.dsc --replicate 20 -c 2
INFO: Checking R library psych ...
INFO: Checking R library dscrutils@stephenslab/dsc/dscrutils ...
INFO: DSC script exported to first_investigation.html
INFO: Constructing DSC from add_winsor_method1.dsc ...
INFO: Building execution graph & running DSC ...
[#########################################] 41 steps processed (141 jobs completed, 280 jobs ignored)
INFO: Building DSC database ...
INFO: DSC complete!
INFO: Elapsed time 33.921 seconds.
Since the addition of the winsor module has no effect on the results generated using the mean and median methods, the DSC program automatically determines that the previously generated results for these methods are still valid, and does not re-run the R code.
Let’s load the results from our new benchmark into R.
dscout3 <- dscquery(dsc.outdir = "dsc_result",
targets = c("simulate","analyze","score.error"))
As before, we can easily create a visual summary of the squared-error results:
create.boxplot(dscout3)
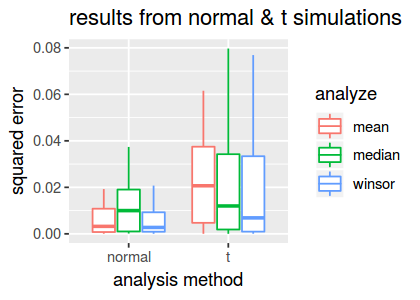
From this plot, we observe that the Winsorized mean estimate is more accurate than both the standard mean and median on the t-distributed data.
Recap
In this tutorial, we presented a very simple example of a DSC benchmark. Despite its simplicity, this example was useful for illustrating some of the essential features of DSC:
-
A DSC experiment can be decomposed into modules;
-
The modules can be organized into module groups;
-
The modules and module groups and combined in sequence, forming pipelines;
-
Pipelines can easily be replicated with different pseudorandom number sequences;
-
The results of a DSC experiment can be conveniently loaded into a data frame in R, and the results can be examined using standard tools and packages in R.
-
When updating or extending a benchmark, DSC generates the results dynamically—that is, DSC determines the minimum computational effort needed to update or extend the results.
Next steps
To learn more about the syntax of the DSC file so that you can develop your own DSCs, move to DSC Basics, Part I.