Automatic Grouping of Factors: Pancreas
Ziang Zhang
2025-02-12
Last updated: 2025-08-01
Checks: 7 0
Knit directory:
single-cell-jamboree/analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(1) was run prior to running the
code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 7b84c17. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/.Rhistory
Ignored: code/.Rhistory
Untracked files:
Untracked: .DS_Store
Untracked: analysis/.DS_Store
Untracked: analysis/mouse_embryo_slide14.Rmd
Untracked: code/.DS_Store
Untracked: code/analysis_mouse_slide14.R
Untracked: code/analysis_mouse_slide14_midway3.R
Untracked: code/mouse_embryo_data_slide_selection.R
Untracked: code/plot_loadings_on_locations.R
Untracked: code/plot_spatialPCs.R
Untracked: code/run_spatialpca.sbatch
Untracked: data/.DS_Store
Untracked: data/mouse_embryo/
Untracked: output/.DS_Store
Untracked: output/mouse_embryo/
Unstaged changes:
Modified: analysis/pancreas_another_look.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/pancreas_group.rmd) and
HTML (docs/pancreas_group.html) files. If you’ve configured
a remote Git repository (see ?wflow_git_remote), click on
the hyperlinks in the table below to view the files as they were in that
past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 7b84c17 | Ziang Zhang | 2025-08-01 | workflowr::wflow_publish("analysis/pancreas_group.rmd") |
| html | 7dddd9b | Ziang Zhang | 2025-04-02 | Build site. |
| Rmd | ac96a01 | Ziang Zhang | 2025-04-02 | workflowr::wflow_publish("analysis/pancreas_group.rmd") |
| html | 529428e | Ziang Zhang | 2025-04-02 | Build site. |
| Rmd | e0006db | Ziang Zhang | 2025-04-02 | workflowr::wflow_publish("analysis/pancreas_group.rmd") |
| html | 44989cf | Ziang Zhang | 2025-02-12 | Build site. |
| Rmd | 36a6139 | Ziang Zhang | 2025-02-12 | workflowr::wflow_publish("pancreas_group.rmd") |
| html | cb4a691 | Ziang Zhang | 2025-02-12 | Build site. |
| Rmd | 69af116 | Ziang Zhang | 2025-02-12 | workflowr::wflow_publish("pancreas_group.rmd") |
Let’s try some automatic grouping of factors for the pancreas dataset, based on the grouping information provided in the metadata.
library(Matrix)
library(fastTopics)Warning: package 'fastTopics' was built under R version 4.3.3library(ggplot2)Warning: package 'ggplot2' was built under R version 4.3.3library(cowplot)
set.seed(1)
subsample_cell_types <- function (x, n = 1000) {
cells <- NULL
groups <- levels(x)
for (g in groups) {
i <- which(x == g)
n0 <- min(n,length(i))
i <- sample(i,n0)
cells <- c(cells,i)
}
return(sort(cells))
}
load("../data/pancreas.RData")
load("../output/pancreas_factors.RData")
load("../output/pancreas_factors2.RData")source("../code/group_factors.R")A Simple Automatic Approach Based on ANOVA
Let \(l_{ki}\) denote the loading of observation \(i\) on the \(k\)th factor, and let \(G_i\) denote the grouping information (e.g. cell-type) for observation (e.g. cell) \(i\). Suppose \(G_i\) can take values in \(\{g_1, g_2, \ldots, g_L\}\) (e.g. \(L\) possible cell-types).
A straightforward way to identify group-specific factors is to perform an ANOVA on each factor’s loadings. Specifically, for the \(k\)th factor, we regress the loadings \(\boldsymbol{l}_k\) on the set of indicator variables \(\{\mathbb{I}(G_i = c_l)\}_{l=1}^L\):
\[ l_{ki} \sim \sum_{l=1}^L \beta_l \,\mathbb{I}(G_i = c_l). \]
From the regression model for each factor, we obtain a statistic \(S_k\) that measures how strongly the grouping structure explains variation in the \(k\)-th factor’s loadings. For instance, \(S_k\) could be the \(R^2\) of this regression model or the \(F\)-statistic from the ANOVA test. After computing \(\{S_k\}_{k=1}^K\), we can rank the factors by their relevance to the grouping, then choose a threshold (for example, by examining an elbow plot) to automatically select the ``group-specific’’ factors.
Below, let’s apply this approach to the pancreas dataset, using \(R^2\) as the relevance statistic.
flashier NMF
cells <- subsample_cell_types(sample_info$celltype,n = 500)
L <- fl_nmf_ldf$L
k <- ncol(L)
colnames(L) <- paste0("k",1:k)Take a look at the elbow plot:
ordered_df_tech <- ANOVA_factors(L[cells,], sample_info$tech[cells], stats = "R2")
ordered_df_celltype <- ANOVA_factors(L[cells,], sample_info$celltype[cells], stats = "R2")
par(mfrow = c(2,1))
plot(ordered_df_tech$rank, ordered_df_tech$stats, type = "o", xlab = "Rank", ylab = "R2", main = "batchtypes", ylim = c(0,1.1))
text(ordered_df_tech$rank, ordered_df_tech$stats, labels = ordered_df_tech$factor, pos = 3, cex = 0.6)
abline(h = c(0.3,0.5,0.7), col = "red", lty = 2)
plot(ordered_df_celltype$rank, ordered_df_celltype$stats, type = "o", xlab = "Rank", ylab = "R2", main = "celltypes", ylim = c(0,1.1))
text(ordered_df_celltype$rank, ordered_df_celltype$stats, labels = ordered_df_celltype$factor, pos = 3, cex = 0.6)
abline(h = c(0.3,0.5,0.7), col = "red", lty = 2)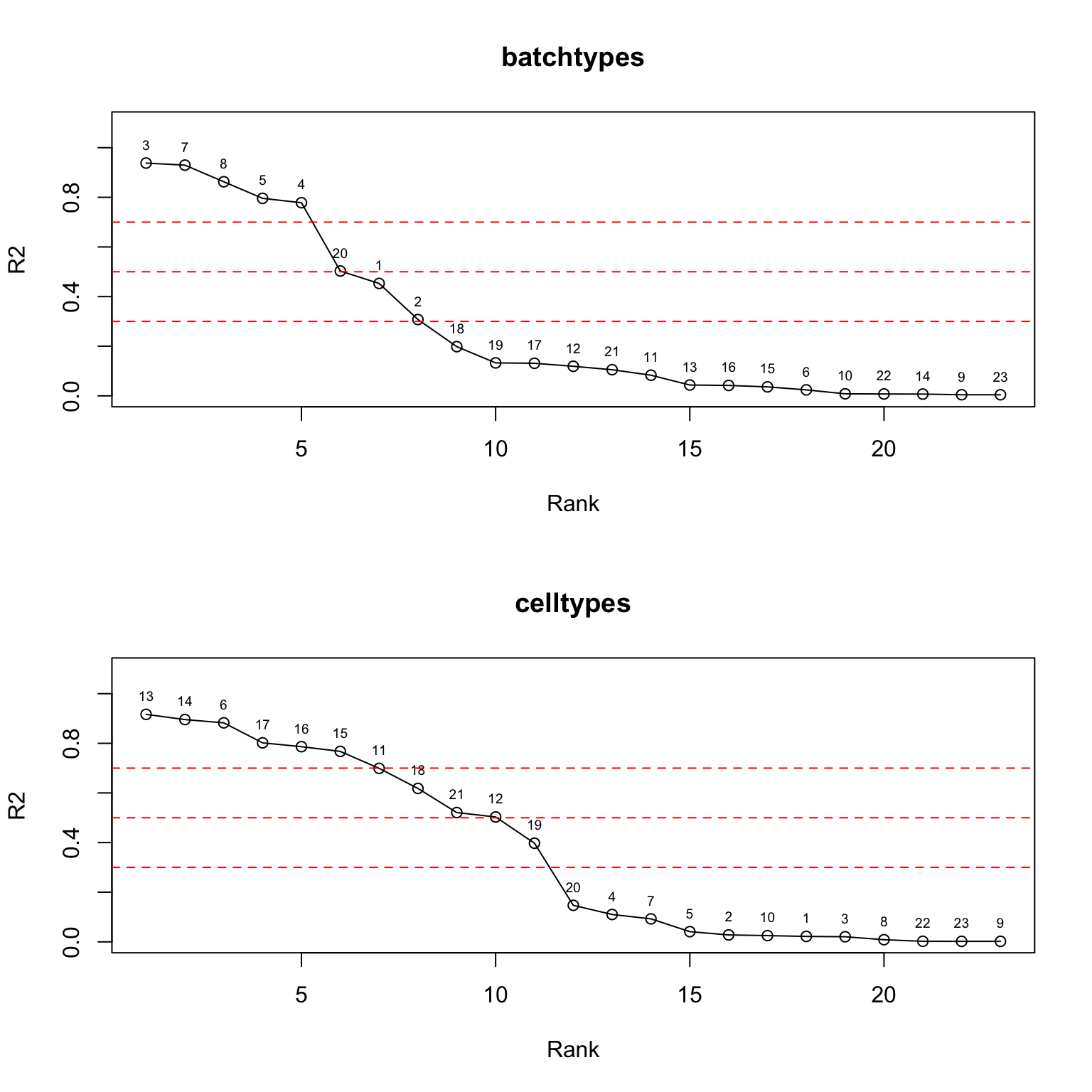
| Version | Author | Date |
|---|---|---|
| cb4a691 | Ziang Zhang | 2025-02-12 |
par(mfrow = c(1,1))Cut off the factors with \(R^2\) less than 0.7:
p1 <- structure_plot_group(L = L[cells,], group_vec = sample_info$tech[cells],
cutoff = 0.7, stats = "R2", group_name = "data-set")
p2 <- structure_plot_group(L = L[cells,], group_vec = sample_info$celltype[cells],
cutoff = 0.7, stats = "R2", group_name = "cell-type")
plot_grid(p1,p2,nrow = 2,ncol = 1)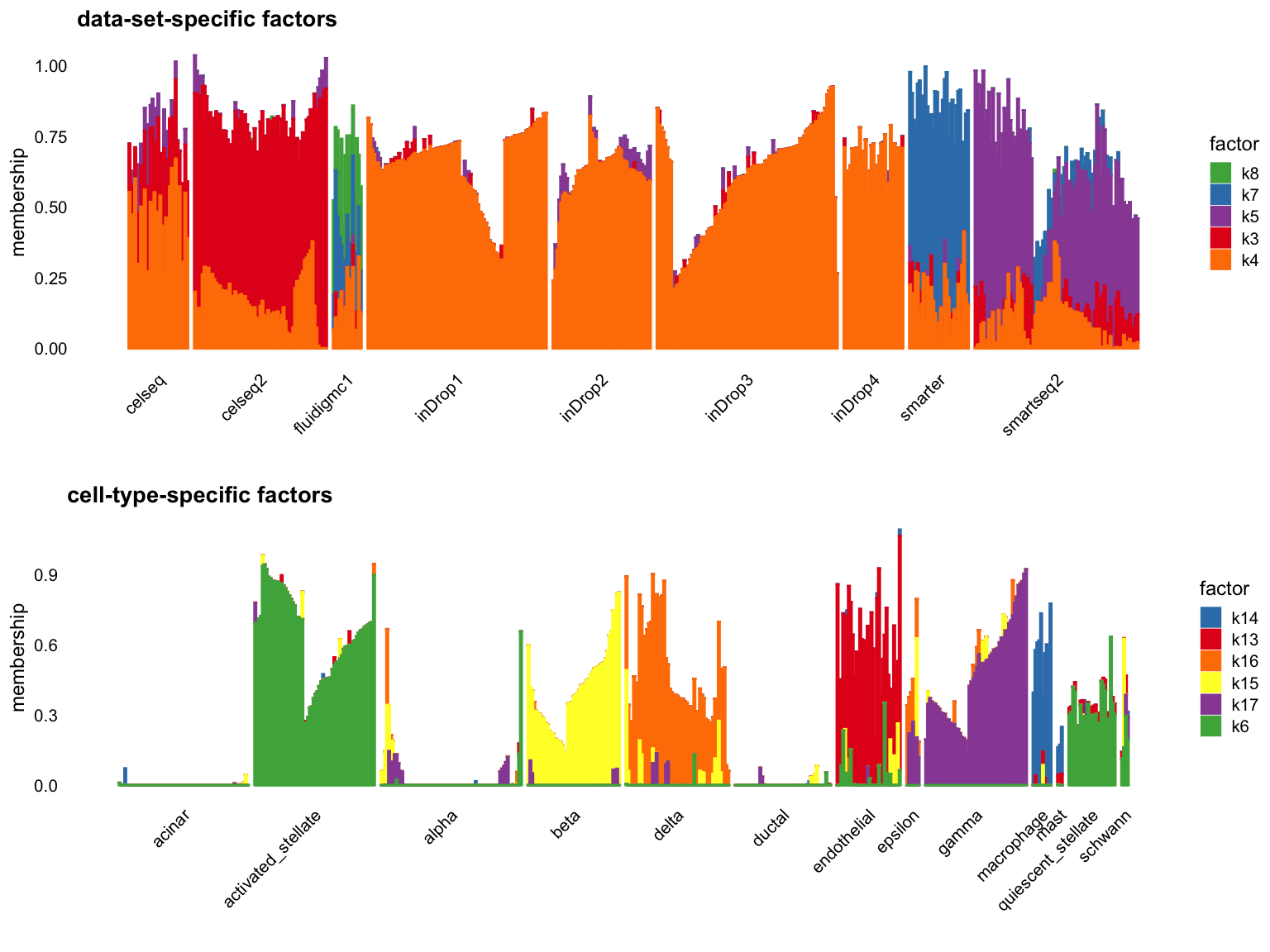
| Version | Author | Date |
|---|---|---|
| cb4a691 | Ziang Zhang | 2025-02-12 |
Cut off the factors with \(R^2\) less than 0.5:
p1 <- structure_plot_group(L = L[cells,], group_vec = sample_info$tech[cells],
cutoff = 0.5, stats = "R2", group_name = "data-set")
p2 <- structure_plot_group(L = L[cells,], group_vec = sample_info$celltype[cells],
cutoff = 0.5, stats = "R2", group_name = "cell-type")
plot_grid(p1,p2,nrow = 2,ncol = 1)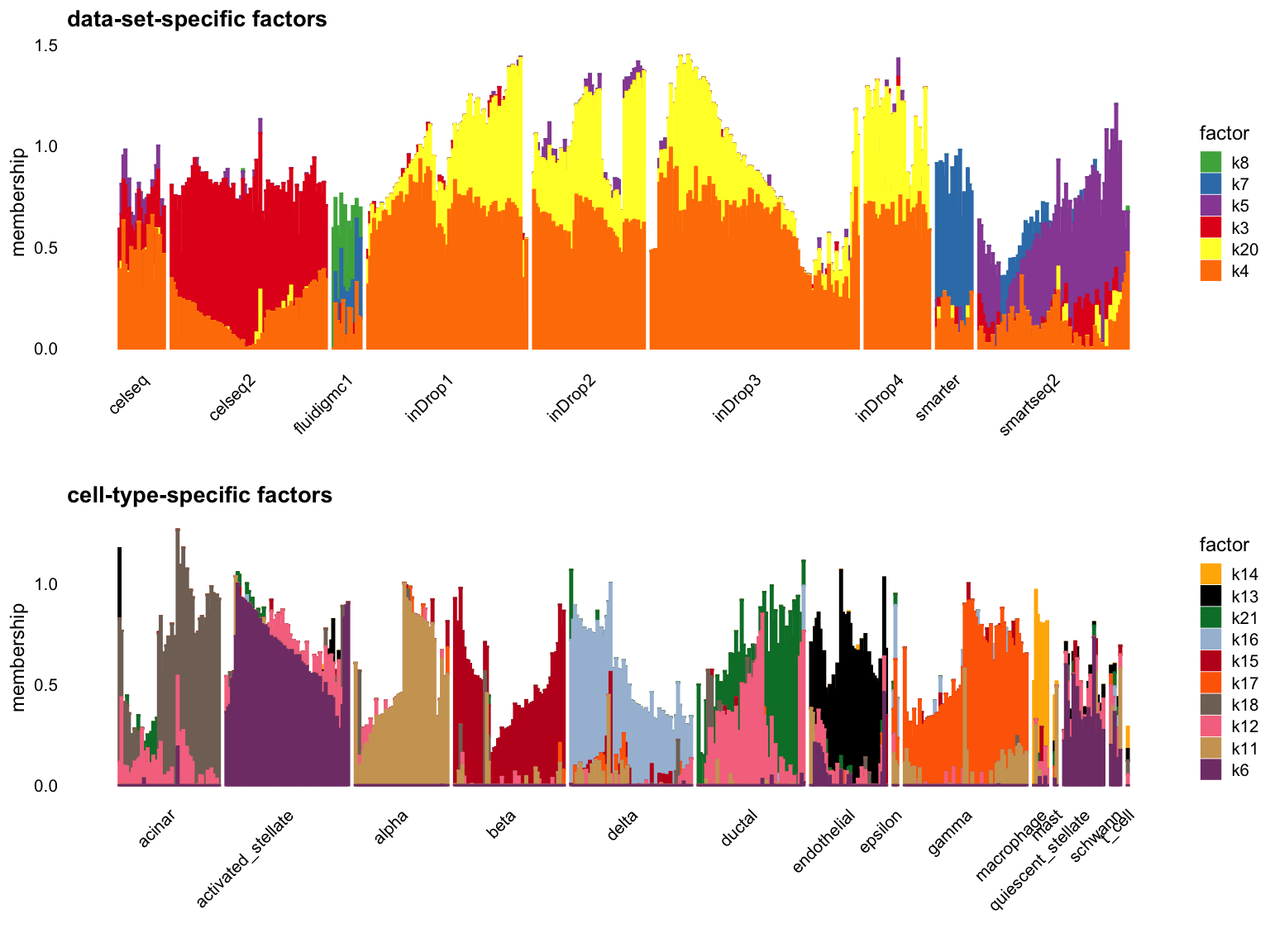
| Version | Author | Date |
|---|---|---|
| cb4a691 | Ziang Zhang | 2025-02-12 |
Try reduce to the cut-off to 0.3:
p1 <- structure_plot_group(L = L[cells,], group_vec = sample_info$tech[cells],
cutoff = 0.3, stats = "R2", group_name = "data-set")
p2 <- structure_plot_group(L = L[cells,], group_vec = sample_info$celltype[cells],
cutoff = 0.3, stats = "R2", group_name = "cell-type")
plot_grid(p1,p2,nrow = 2,ncol = 1)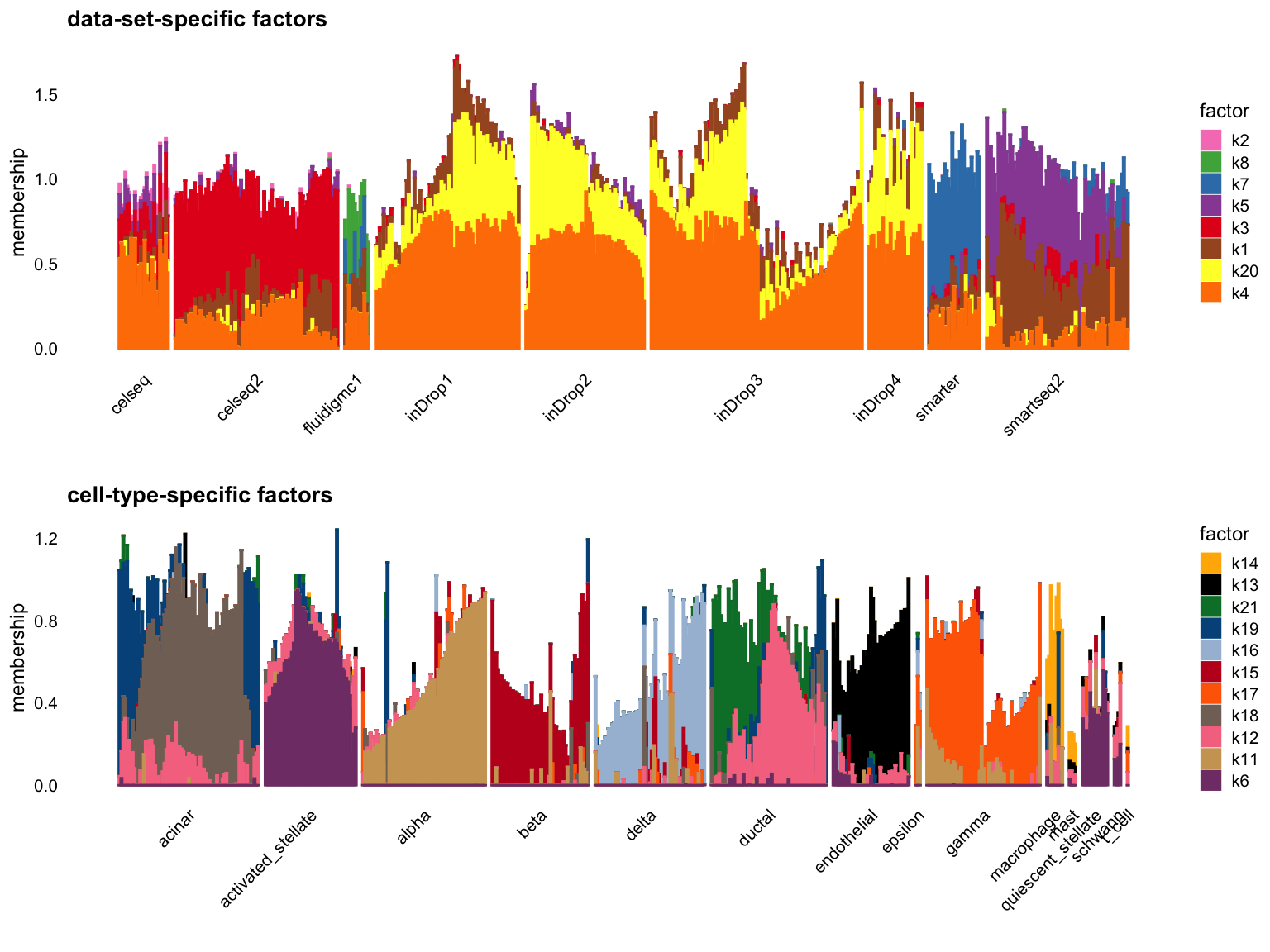
| Version | Author | Date |
|---|---|---|
| cb4a691 | Ziang Zhang | 2025-02-12 |
NMF (NNLM)
W <- nmf$W
k <- ncol(W)
d <- apply(W,2,max)
scale_cols <- function (A, b)
t(t(A) * b)
W <- scale_cols(W,1/d)
colnames(W) <- paste0("k",1:k)Take a look at the elbow plot:
ordered_df_tech <- ANOVA_factors(W[cells,], sample_info$tech[cells], stats = "R2")
ordered_df_celltype <- ANOVA_factors(W[cells,], sample_info$celltype[cells], stats = "R2")
par(mfrow = c(2,1))
plot(ordered_df_tech$rank, ordered_df_tech$stats, type = "o", xlab = "Rank", ylab = "R2", main = "batchtypes", ylim = c(0,1.1))
text(ordered_df_tech$rank, ordered_df_tech$stats, labels = ordered_df_tech$factor, pos = 3, cex = 0.6)
abline(h = c(0.3,0.5,0.7), col = "red", lty = 2)
plot(ordered_df_celltype$rank, ordered_df_celltype$stats, type = "o", xlab = "Rank", ylab = "R2", main = "celltypes", ylim = c(0,1.1))
text(ordered_df_celltype$rank, ordered_df_celltype$stats, labels = ordered_df_celltype$factor, pos = 3, cex = 0.6)
abline(h = c(0.3,0.5,0.7), col = "red", lty = 2)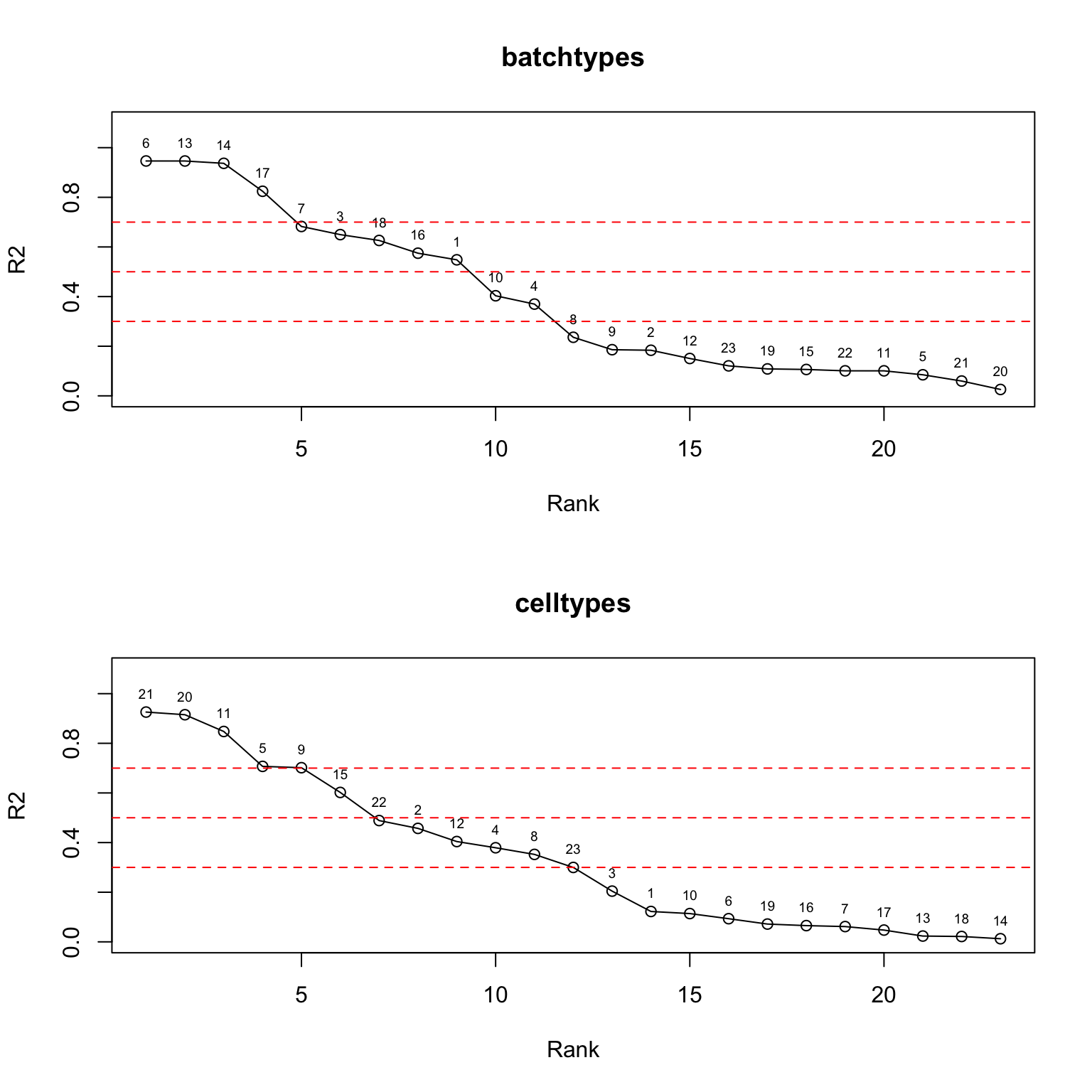
| Version | Author | Date |
|---|---|---|
| cb4a691 | Ziang Zhang | 2025-02-12 |
par(mfrow = c(1,1))Cut off the factors with \(R^2\) less than 0.7:
p1 <- structure_plot_group(L = W[cells,], group_vec = sample_info$tech[cells],
cutoff = 0.7, stats = "R2", group_name = "data-set")
p2 <- structure_plot_group(L = W[cells,], group_vec = sample_info$celltype[cells],
cutoff = 0.7, stats = "R2", group_name = "cell-type")
plot_grid(p1,p2,nrow = 2,ncol = 1)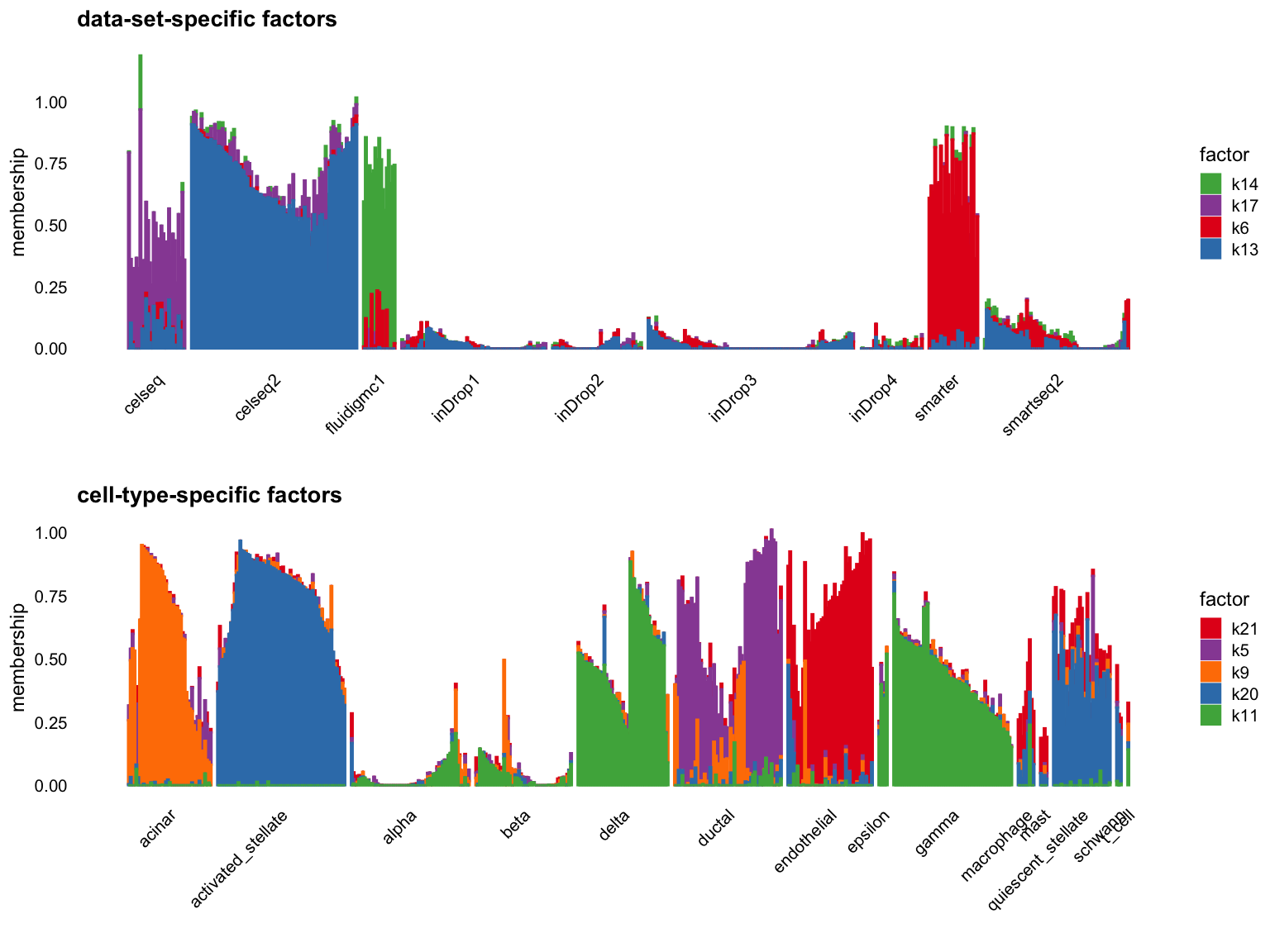
| Version | Author | Date |
|---|---|---|
| cb4a691 | Ziang Zhang | 2025-02-12 |
Cut off the factors with \(R^2\) less than 0.5:
p1 <- structure_plot_group(L = W[cells,], group_vec = sample_info$tech[cells],
cutoff = 0.5, stats = "R2", group_name = "data-set")
p2 <- structure_plot_group(L = W[cells,], group_vec = sample_info$celltype[cells],
cutoff = 0.5, stats = "R2", group_name = "cell-type")
plot_grid(p1,p2,nrow = 2,ncol = 1)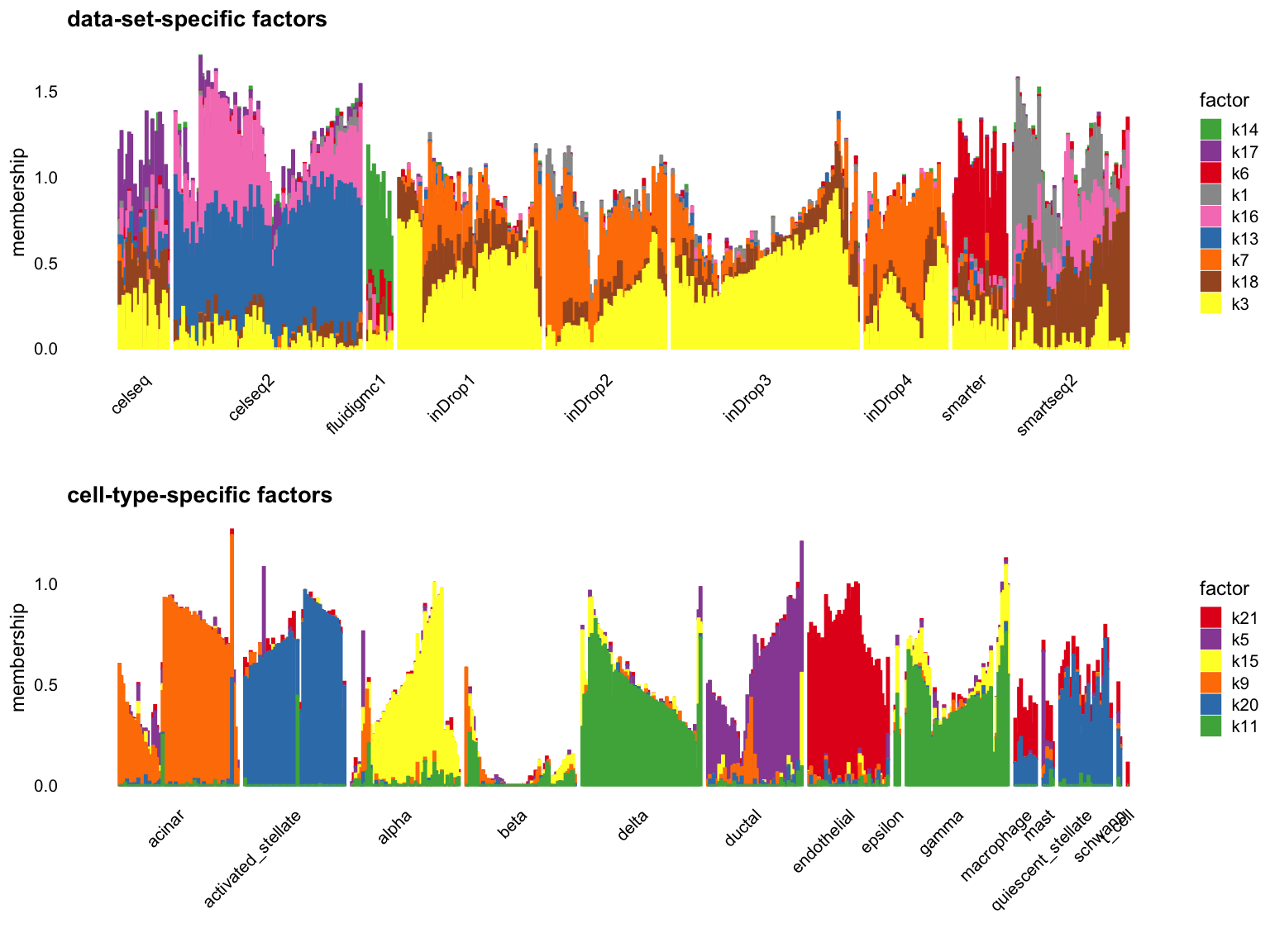
| Version | Author | Date |
|---|---|---|
| cb4a691 | Ziang Zhang | 2025-02-12 |
Cut off the factors with \(R^2\) less than 0.3:
p1 <- structure_plot_group(L = W[cells,], group_vec = sample_info$tech[cells],
cutoff = 0.3, stats = "R2", group_name = "data-set")
p2 <- structure_plot_group(L = W[cells,], group_vec = sample_info$celltype[cells],
cutoff = 0.3, stats = "R2", group_name = "cell-type")
plot_grid(p1,p2,nrow = 2,ncol = 1)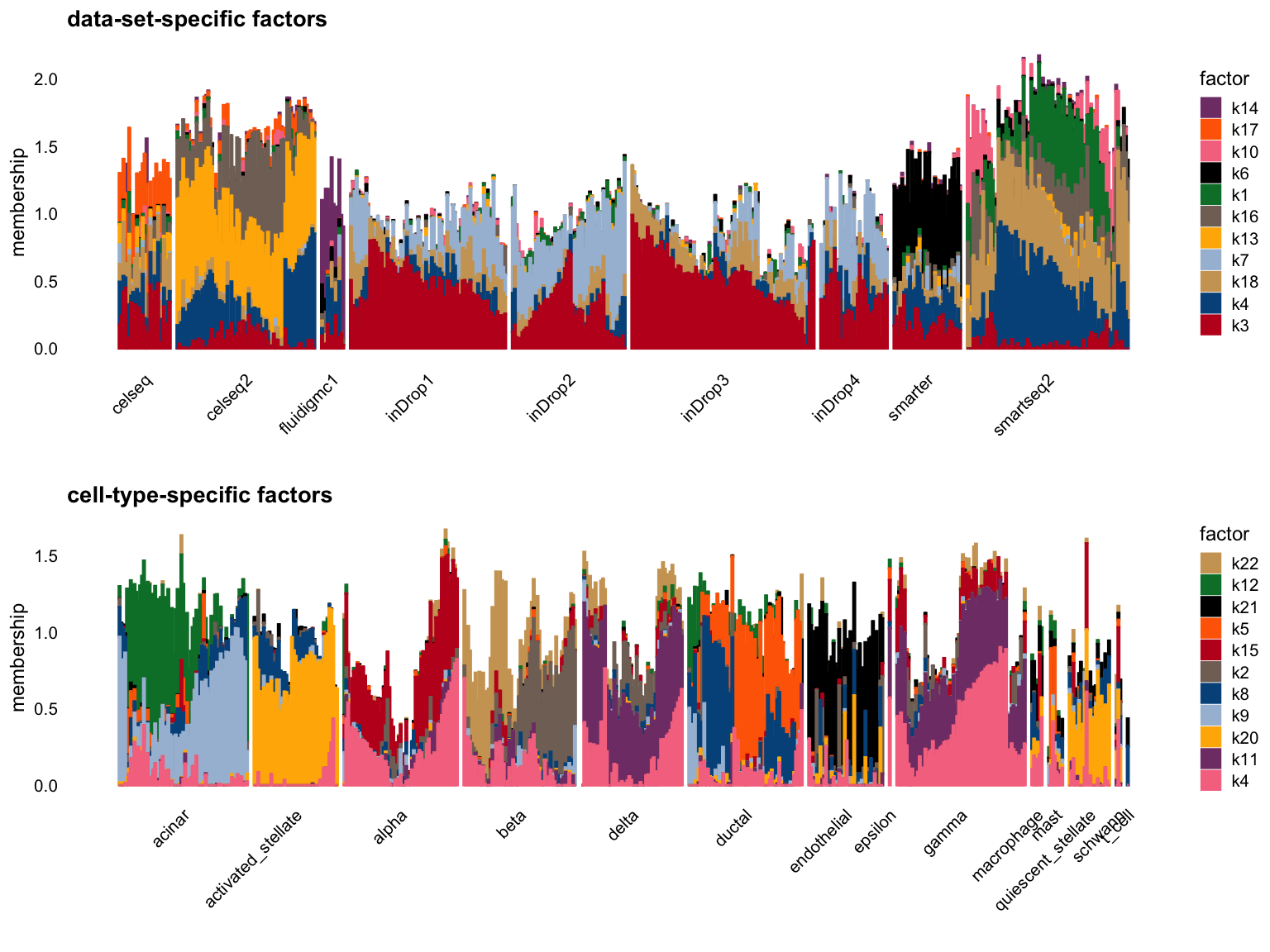
| Version | Author | Date |
|---|---|---|
| cb4a691 | Ziang Zhang | 2025-02-12 |
Topic model (fastTopics)
L <- poisson2multinom(pnmf)$LTake a look at the elbow plot:
ordered_df_tech <- ANOVA_factors(L[cells,], sample_info$tech[cells], stats = "R2")
ordered_df_celltype <- ANOVA_factors(L[cells,], sample_info$celltype[cells], stats = "R2")
par(mfrow = c(2,1))
plot(ordered_df_tech$rank, ordered_df_tech$stats, type = "o", xlab = "Rank", ylab = "R2", main = "batchtypes", ylim = c(0,1.1))
text(ordered_df_tech$rank, ordered_df_tech$stats, labels = ordered_df_tech$factor, pos = 3, cex = 0.6)
abline(h = c(0.3,0.5,0.7), col = "red", lty = 2)
plot(ordered_df_celltype$rank, ordered_df_celltype$stats, type = "o", xlab = "Rank", ylab = "R2", main = "celltypes", ylim = c(0,1.1))
text(ordered_df_celltype$rank, ordered_df_celltype$stats, labels = ordered_df_celltype$factor, pos = 3, cex = 0.6)
abline(h = c(0.3,0.5,0.7), col = "red", lty = 2)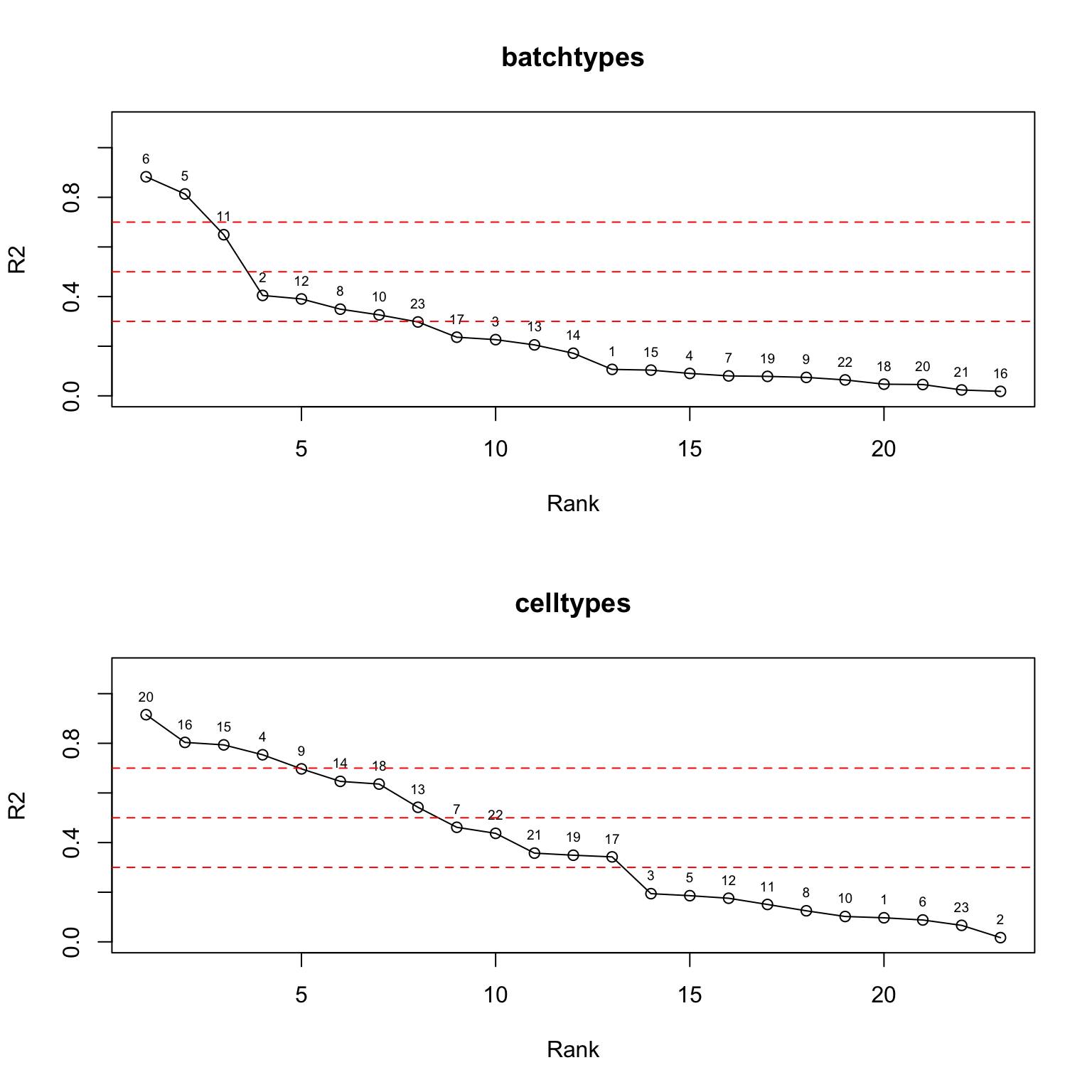
| Version | Author | Date |
|---|---|---|
| cb4a691 | Ziang Zhang | 2025-02-12 |
par(mfrow = c(1,1))Cut off the factors with \(R^2\) less than 0.7:
p1 <- structure_plot_group(L = L[cells,], group_vec = sample_info$tech[cells],
cutoff = 0.7, stats = "R2", group_name = "data-set")
p2 <- structure_plot_group(L = L[cells,], group_vec = sample_info$celltype[cells],
cutoff = 0.7, stats = "R2", group_name = "cell-type")
plot_grid(p1,p2,nrow = 2,ncol = 1)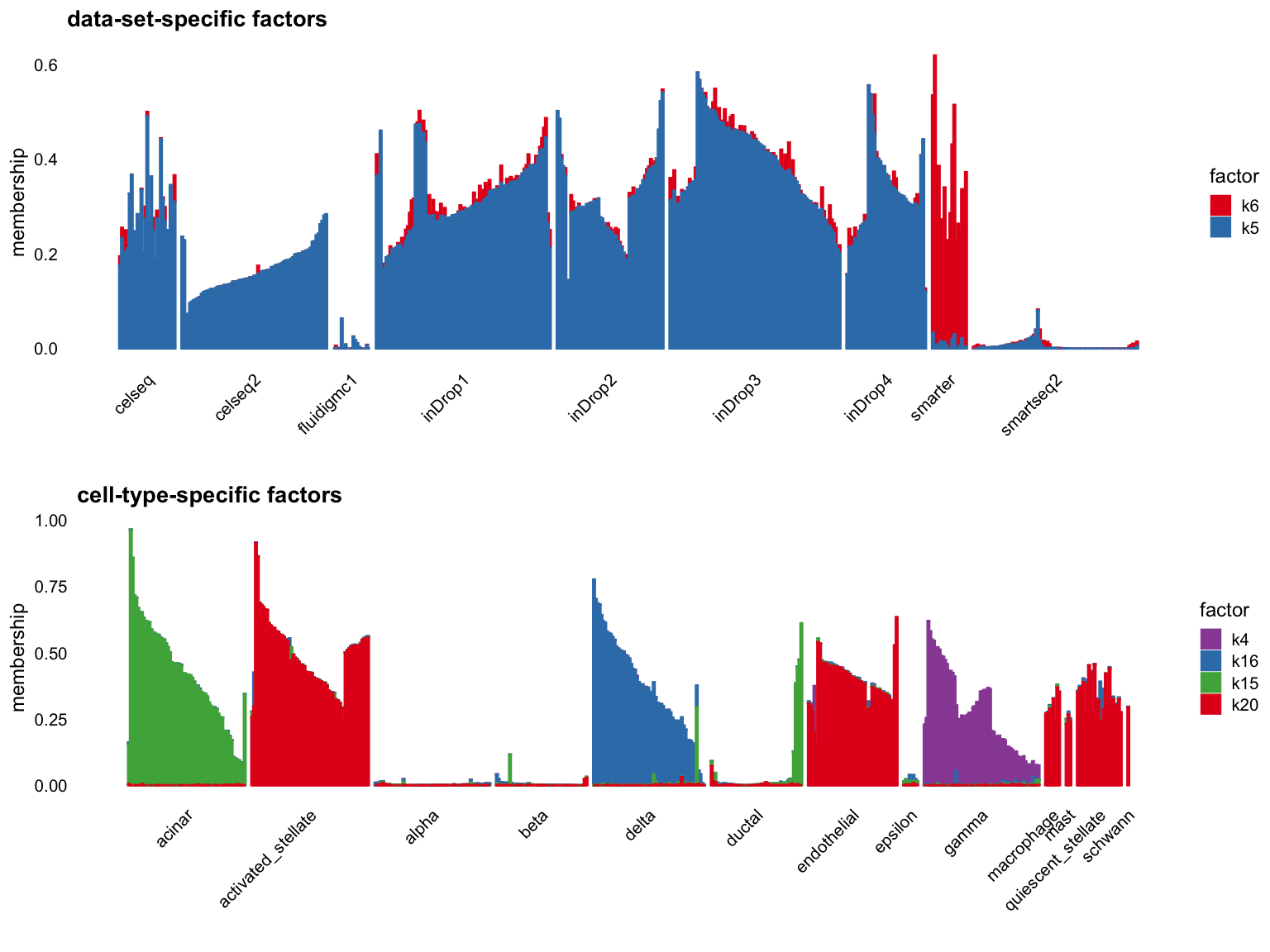
| Version | Author | Date |
|---|---|---|
| cb4a691 | Ziang Zhang | 2025-02-12 |
Cut off the factors with \(R^2\) less than 0.5:
p1 <- structure_plot_group(L = L[cells,], group_vec = sample_info$tech[cells],
cutoff = 0.5, stats = "R2", group_name = "data-set")
p2 <- structure_plot_group(L = L[cells,], group_vec = sample_info$celltype[cells],
cutoff = 0.5, stats = "R2", group_name = "cell-type")
plot_grid(p1,p2,nrow = 2,ncol = 1)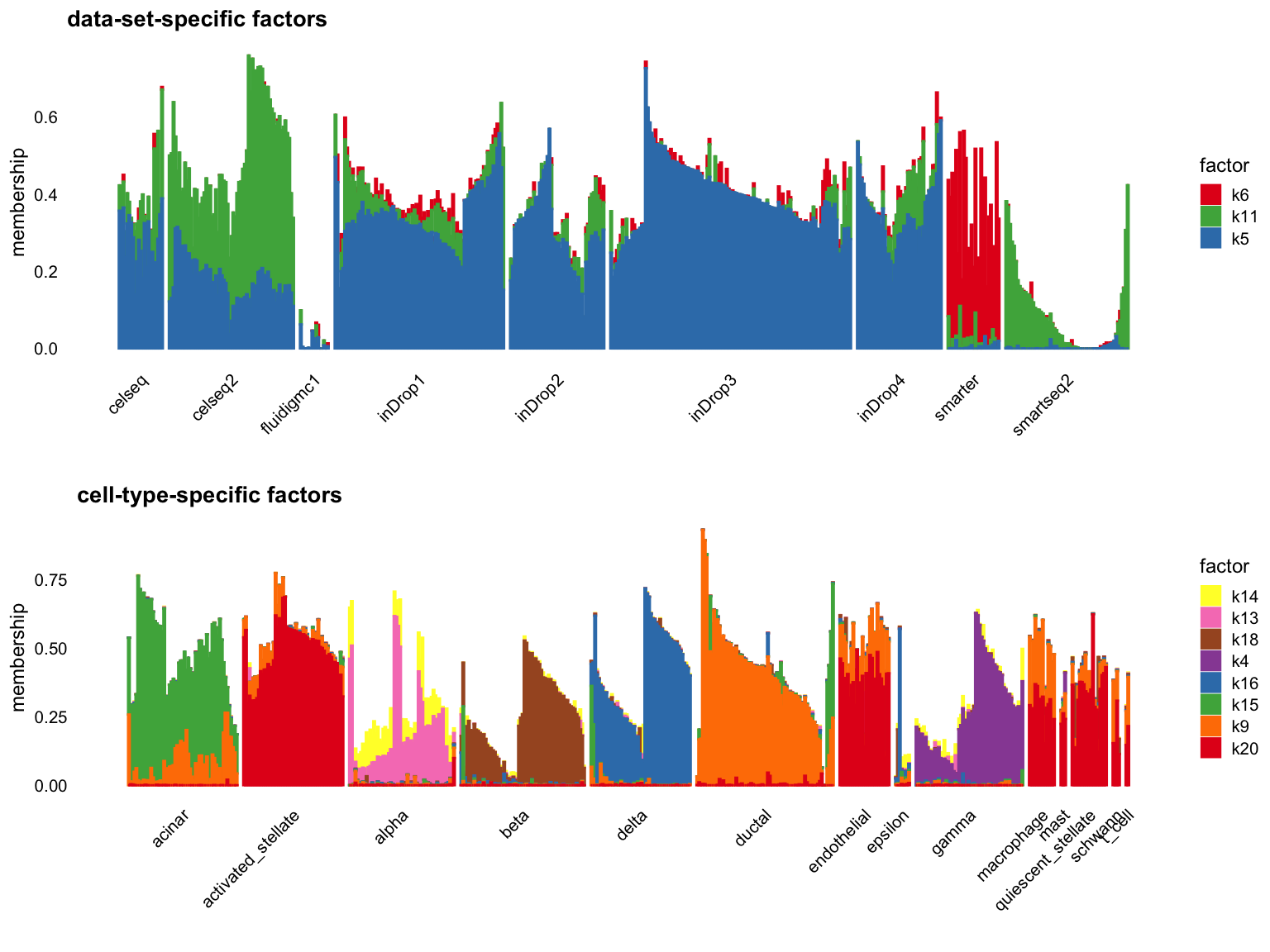
| Version | Author | Date |
|---|---|---|
| cb4a691 | Ziang Zhang | 2025-02-12 |
Cut off the factors with \(R^2\) less than 0.3:
p1 <- structure_plot_group(L = L[cells,], group_vec = sample_info$tech[cells],
cutoff = 0.3, stats = "R2", group_name = "data-set")
p2 <- structure_plot_group(L = L[cells,], group_vec = sample_info$celltype[cells],
cutoff = 0.3, stats = "R2", group_name = "cell-type")
plot_grid(p1,p2,nrow = 2,ncol = 1)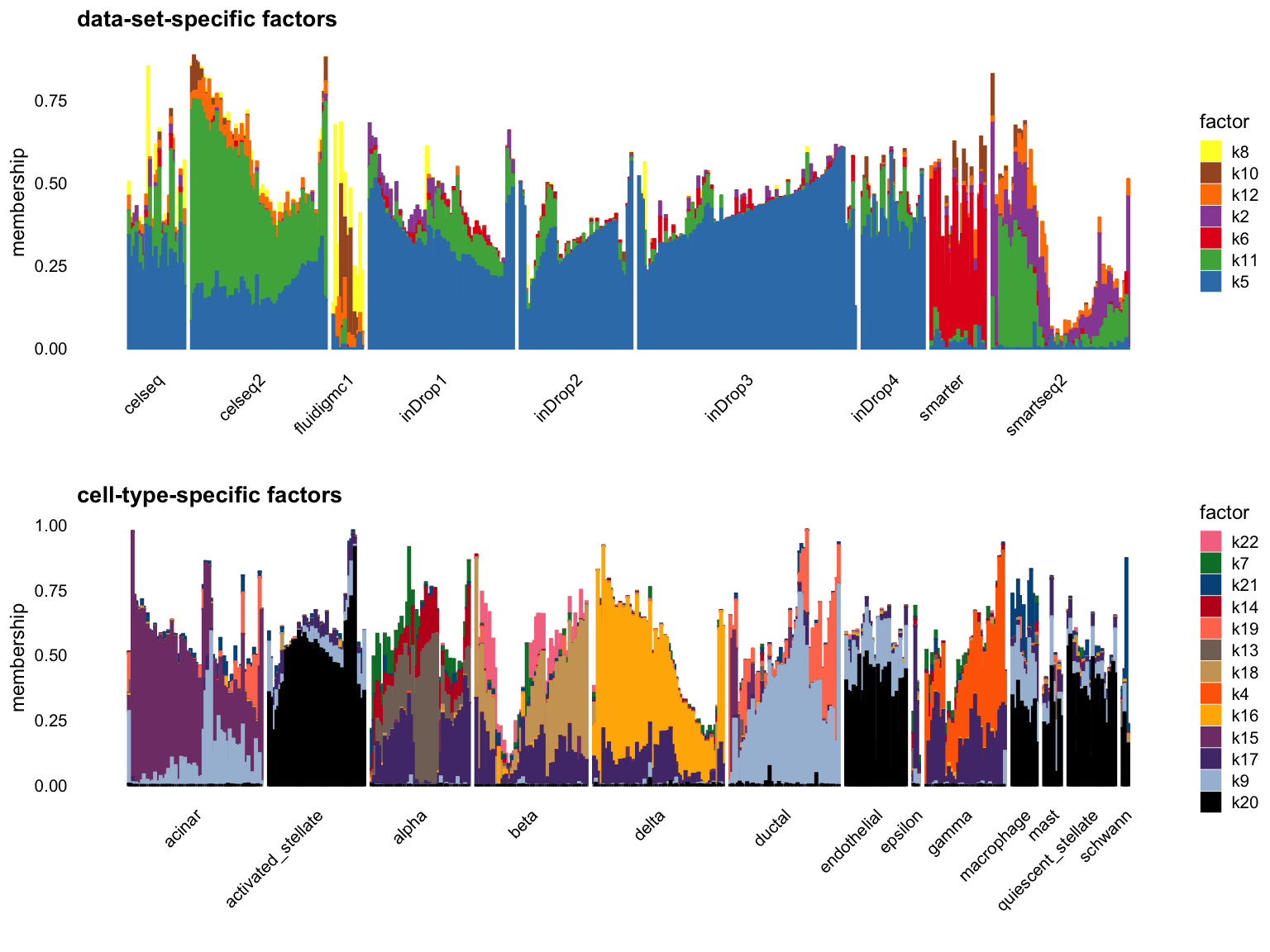
| Version | Author | Date |
|---|---|---|
| cb4a691 | Ziang Zhang | 2025-02-12 |
Flashier semi-NMF
L <- fl_snmf_ldf$L
x <- apply(L,2,function (x) quantile(x,0.995))
L <- scale_cols(L,1/x)
colnames(L) <- paste0("k",1:k)Take a look at the elbow plot:
ordered_df_tech <- ANOVA_factors(L[cells,], sample_info$tech[cells], stats = "R2")
ordered_df_celltype <- ANOVA_factors(L[cells,], sample_info$celltype[cells], stats = "R2")
par(mfrow = c(2,1))
plot(ordered_df_tech$rank, ordered_df_tech$stats, type = "o", xlab = "Rank", ylab = "R2", main = "batchtypes", ylim = c(0,1.1))
text(ordered_df_tech$rank, ordered_df_tech$stats, labels = ordered_df_tech$factor, pos = 3, cex = 0.6)
abline(h = c(0.3,0.5,0.7), col = "red", lty = 2)
plot(ordered_df_celltype$rank, ordered_df_celltype$stats, type = "o", xlab = "Rank", ylab = "R2", main = "celltypes", ylim = c(0,1.1))
text(ordered_df_celltype$rank, ordered_df_celltype$stats, labels = ordered_df_celltype$factor, pos = 3, cex = 0.6)
abline(h = c(0.3,0.5,0.7), col = "red", lty = 2)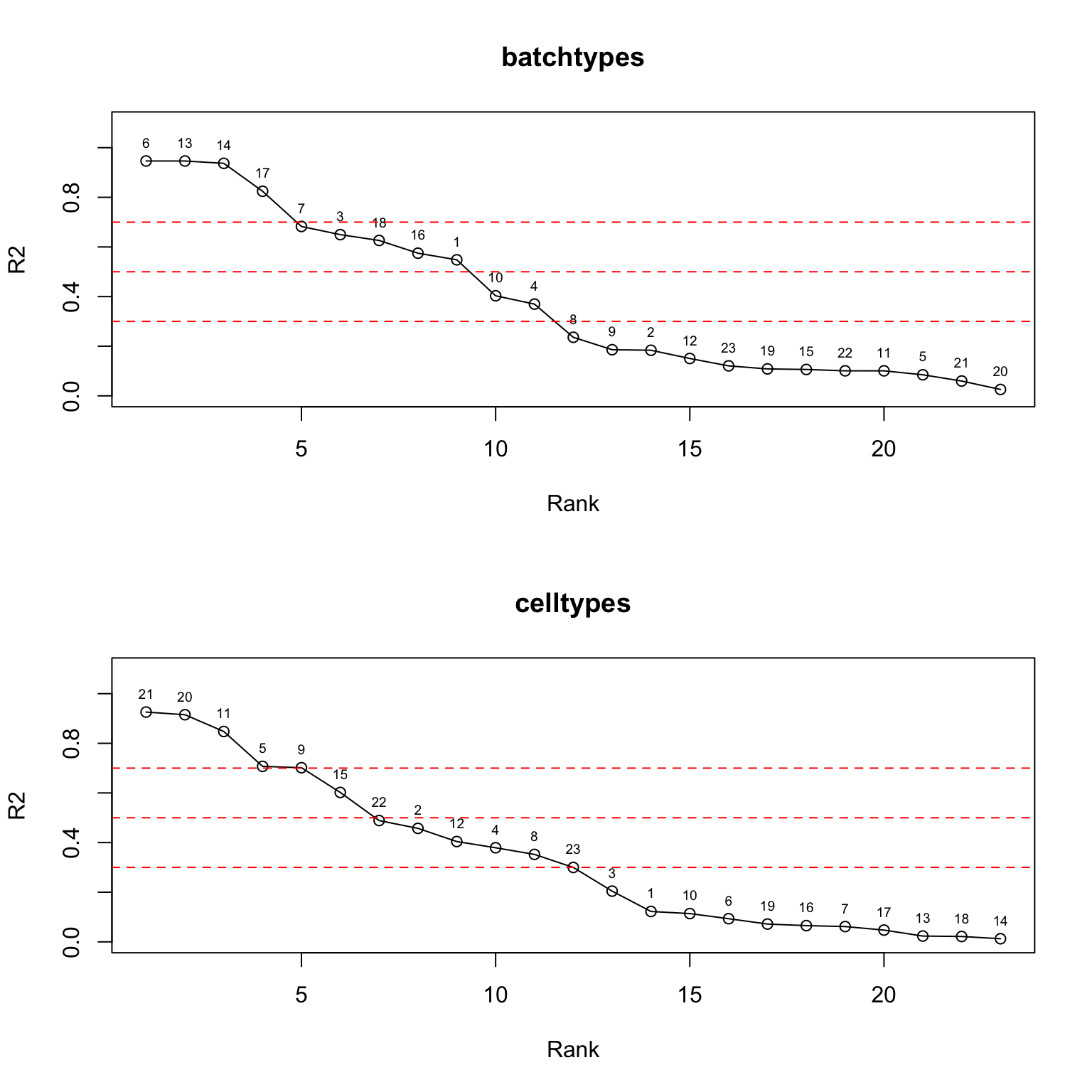
par(mfrow = c(1,1))Cut off the factors with \(R^2\) less than 0.7:
p1 <- structure_plot_group(L = L[cells,], group_vec = sample_info$tech[cells],
cutoff = 0.7, stats = "R2", group_name = "data-set")
p2 <- structure_plot_group(L = L[cells,], group_vec = sample_info$celltype[cells],
cutoff = 0.7, stats = "R2", group_name = "cell-type")
plot_grid(p1,p2,nrow = 2,ncol = 1)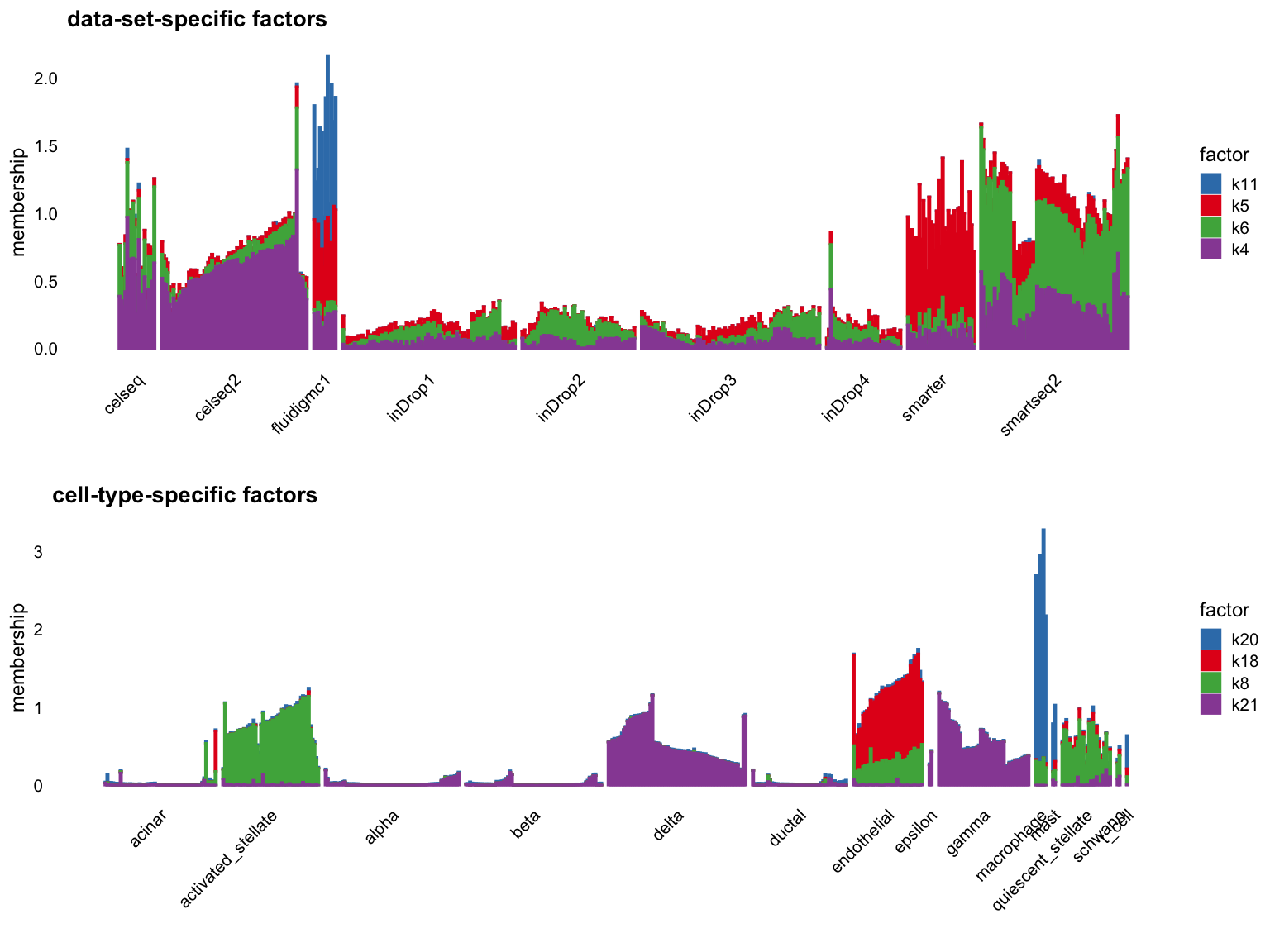
| Version | Author | Date |
|---|---|---|
| cb4a691 | Ziang Zhang | 2025-02-12 |
Cut off the factors with \(R^2\) less than 0.5:
p1 <- structure_plot_group(L = L[cells,], group_vec = sample_info$tech[cells],
cutoff = 0.5, stats = "R2", group_name = "data-set")
p2 <- structure_plot_group(L = L[cells,], group_vec = sample_info$celltype[cells],
cutoff = 0.5, stats = "R2", group_name = "cell-type")
plot_grid(p1,p2,nrow = 2,ncol = 1)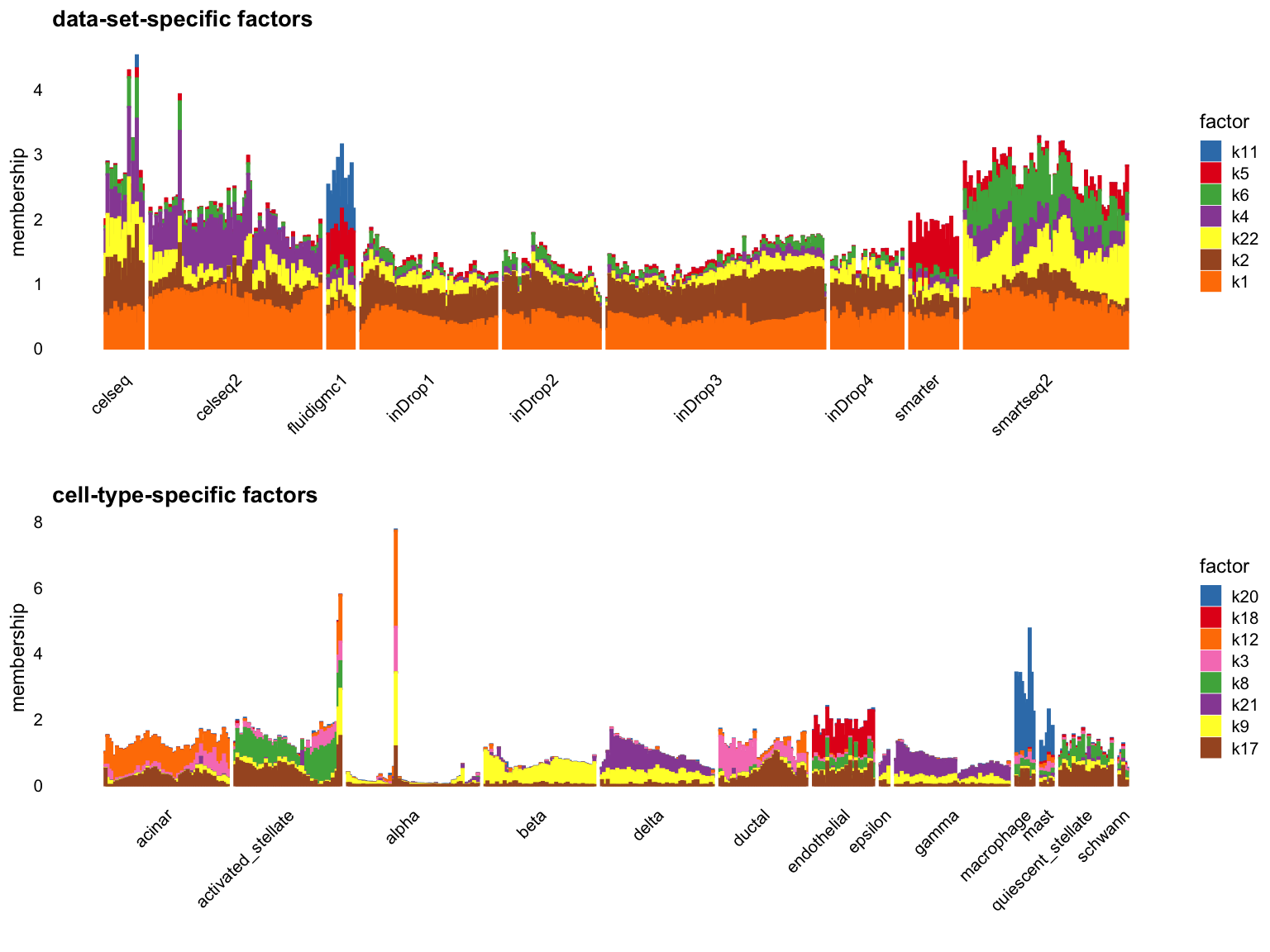
| Version | Author | Date |
|---|---|---|
| cb4a691 | Ziang Zhang | 2025-02-12 |
Cut off the factors with \(R^2\) less than 0.3:
p1 <- structure_plot_group(L = L[cells,], group_vec = sample_info$tech[cells],
cutoff = 0.3, stats = "R2", group_name = "data-set")
p2 <- structure_plot_group(L = L[cells,], group_vec = sample_info$celltype[cells],
cutoff = 0.3, stats = "R2", group_name = "cell-type")
plot_grid(p1,p2,nrow = 2,ncol = 1)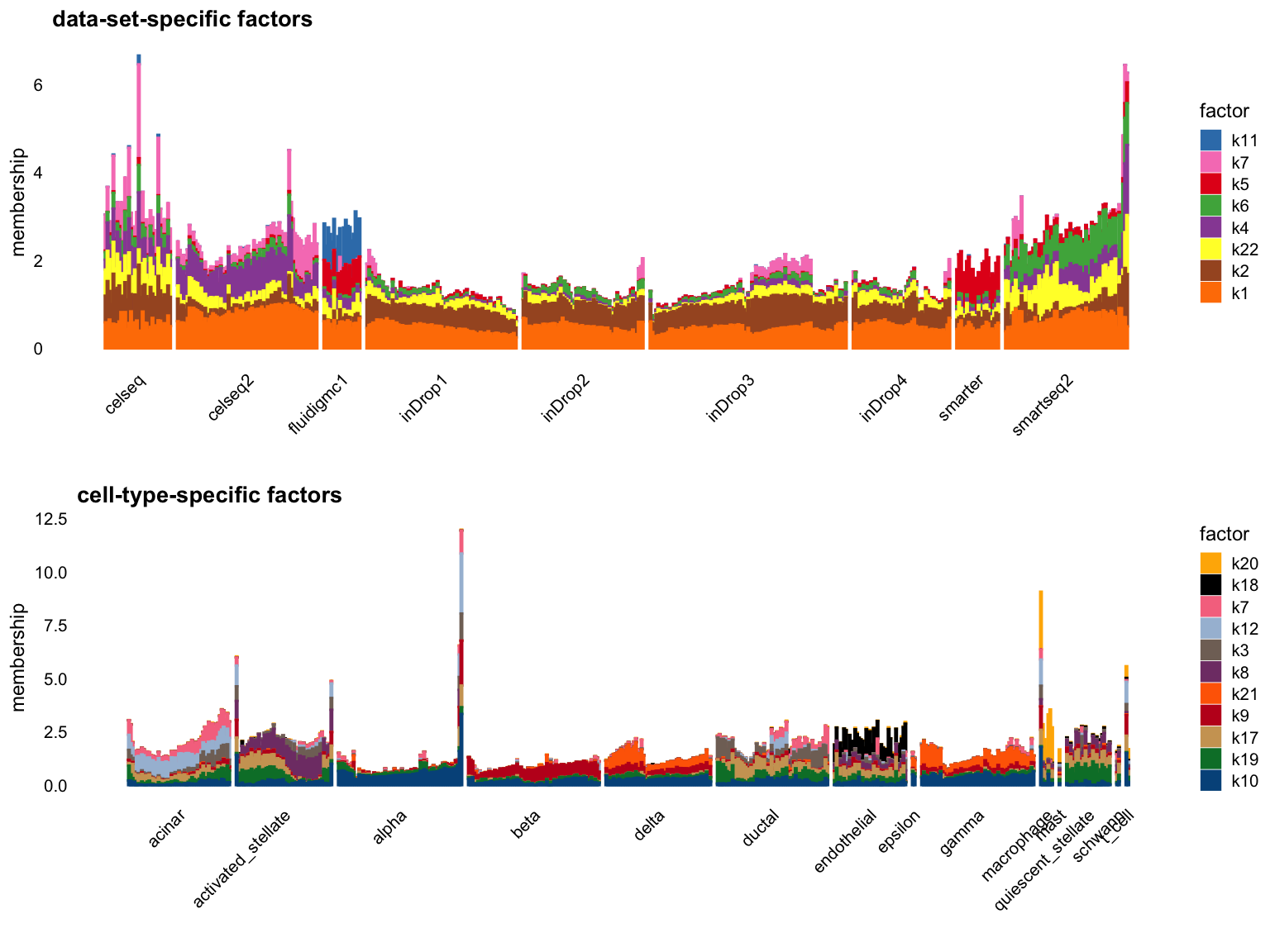
| Version | Author | Date |
|---|---|---|
| cb4a691 | Ziang Zhang | 2025-02-12 |
sessionInfo()R version 4.3.1 (2023-06-16)
Platform: aarch64-apple-darwin20 (64-bit)
Running under: macOS 15.5
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: America/Chicago
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] cowplot_1.1.3 ggplot2_3.5.2 fastTopics_0.6-192 Matrix_1.6-4
loaded via a namespace (and not attached):
[1] gtable_0.3.6 xfun_0.52 bslib_0.9.0
[4] htmlwidgets_1.6.4 ggrepel_0.9.6 lattice_0.22-6
[7] quadprog_1.5-8 vctrs_0.6.5 tools_4.3.1
[10] generics_0.1.4 parallel_4.3.1 tibble_3.2.1
[13] pkgconfig_2.0.3 data.table_1.16.2 SQUAREM_2021.1
[16] RColorBrewer_1.1-3 RcppParallel_5.1.9 lifecycle_1.0.4
[19] truncnorm_1.0-9 compiler_4.3.1 farver_2.1.2
[22] stringr_1.5.1 git2r_0.33.0 progress_1.2.3
[25] RhpcBLASctl_0.23-42 httpuv_1.6.16 htmltools_0.5.8.1
[28] sass_0.4.10 yaml_2.3.10 lazyeval_0.2.2
[31] plotly_4.10.4 later_1.4.2 pillar_1.10.2
[34] crayon_1.5.3 jquerylib_0.1.4 whisker_0.4.1
[37] tidyr_1.3.1 uwot_0.1.16 cachem_1.1.0
[40] gtools_3.9.5 tidyselect_1.2.1 digest_0.6.37
[43] Rtsne_0.17 stringi_1.8.7 dplyr_1.1.4
[46] purrr_1.0.4 ashr_2.2-66 labeling_0.4.3
[49] rprojroot_2.0.4 fastmap_1.2.0 grid_4.3.1
[52] cli_3.6.5 invgamma_1.1 magrittr_2.0.3
[55] withr_3.0.2 prettyunits_1.2.0 scales_1.4.0
[58] promises_1.3.3 rmarkdown_2.28 httr_1.4.7
[61] workflowr_1.7.1 hms_1.1.3 pbapply_1.7-2
[64] evaluate_1.0.3 knitr_1.50 irlba_2.3.5.1
[67] viridisLite_0.4.2 rlang_1.1.6 Rcpp_1.0.14
[70] mixsqp_0.3-54 glue_1.8.0 rstudioapi_0.16.0
[73] jsonlite_2.0.0 R6_2.6.1 fs_1.6.6