Dissecting tumor transcriptional heterogeneity from multi-tumor single-cell RNA-seq data using GBCD
Yusha Liu
Last updated: 2023-08-18
Checks: 7 0
Knit directory: gbcd-workflow/analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(1) was run prior to running the
code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version a78ffef. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Untracked files:
Untracked: .DS_Store
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/gbcd_hnscc_intro.Rmd) and
HTML (docs/gbcd_hnscc_intro.html) files. If you’ve
configured a remote Git repository (see ?wflow_git_remote),
click on the hyperlinks in the table below to view the files as they
were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | a78ffef | YushaLiu | 2023-08-18 | Add installation instructions |
| html | 56bcb81 | Peter Carbonetto | 2023-08-09 | A few fixes to the gbcd_hnscc_intro analysis. |
| Rmd | f2b1d24 | Peter Carbonetto | 2023-08-09 | workflowr::wflow_publish("gbcd_hnscc_intro.Rmd", verbose = TRUE) |
| html | d40f7d0 | Peter Carbonetto | 2023-08-09 | Built the gbcd_hnscc_intro workflowr page. |
| Rmd | f9fe46d | Peter Carbonetto | 2023-08-09 | workflowr::wflow_publish("gbcd_hnscc_intro.Rmd", verbose = TRUE) |
Overview
This vignette shows how to apply “generalized binary covariance decomposition” (GBCD) to jointly analyze single-cell RNA-seq (scRNA-seq) data from malignant cells collected from multiple patients and/or studies, using a head and neck squamous cell carcinoma (HNSCC) dataset from Puram et al. 2017.
GBCD can effectively dissect tumor transcriptional heterogeneity into patient/study-specific and shared gene expression programs (GEPs). GBCD is “unsupervised” in that, unlike tumor-by-tumor (e.g., Puram et al. (2017)) and many harmonization approaches (e.g., Harmony, Liger), it does not use information about which cell comes from which tumor or study. Instead, GBCD only requires the combined scRNA-seq data from all tumors, which are stored as an \(N \times J\) matrix \(Y\) of expression values with entries \(y_{ij}\), where \(i=1,\dots,N\) indexes malignant cells and \(j=1,\dots,J\) indexes genes. In typical applications, \(Y\) contains log-transformed pseudo-count-modified UMI counts (“log-pc counts”).
GBCD ultimately yields a decomposition of the expression data matrix \(Y\) into matrices \(L\) and \(F\) such that \(Y \approx L F^T\), or equivalently, \[y_{ij} \approx \sum_{k=1}^K l_{ik} f_{jk}.\] The \(K\) components should be interpretable as GEPs, with \(l_{ik}\) representing the membership of cell \(i\) in GEP \(k\), and \(f_{jk}\) representing the effect of GEP \(k\) on the expression of gene \(j\). When \(y_{ij}\) are log-pc counts, each \(f_{jk}\) approximately represents the log-fold change (LFC) associated with membership in GEP \(k\), so we refer to the \(f_{jk}\) values as LFCs, and to the vector of LFCs \((f_{1k}, \dots, f_{Jk})^T\) as the “signature” of GEP \(k\).
We begin our analysis by loading the R packages used in the analysis, as well as some custom functions implementing the GBCD model fitting and interpretation.. Then we show how to apply GBCD to the HNSCC dataset step-by-step.
library(ggplot2)
library(cowplot)
library(RColorBrewer)
library(ggrepel)
library(pheatmap)
library(gridExtra)
library(Seurat)
library(Matrix)
library(ebnm)
library(flashier)
library(magrittr)
library(ashr)
source("../code/fit_cov_ebnmf.R")The HNSCC dataset
This data set contains gene expression data for n = 2,176 malignant cells collected in primary tumors from 10 HNSCC patients, as well as matching lymph node (LN) metastases from 5 of these patients. Puram et al. (2017) found that each of these 10 patients mapped to a molecular subtype of HNSCC, whose signatures were previously defined by analysis of bulk expression data of 279 TCGA HNSCC tumors.
Unlike more recently generated data sets, the HNSCC data are not UMI counts; rather, they are read counts produced by SMART-Seq2. Following Puram et al. (2017), we define the transformed counts as \(y_{ij} = \log_2(1 + \mathrm{TPM}_{ij}/10)\), where \(\mathrm{TPM}_{ij}\) is the transcript-per-million (TPM) value for gene \(j\) in cell \(i\).
load("../hnscc/hnscc.RData")
dim(Y)
print(head(info),row.names = FALSE)
# [1] 2176 17113
# cell.id lymph.node cancer.cell cell.type sample.id subject
# HN26_P14_D11_S239_comb 1 1 0 T26 MEEI26_LN
# HN26_P25_H09_S189_comb 1 1 0 T26 MEEI26_LN
# HN26_P14_H06_S282_comb 1 1 0 T26 MEEI26_LN
# HN25_P25_C04_S316_comb 1 1 0 T25 MEEI25_LN
# HN26_P25_C09_S129_comb 1 1 0 T26 MEEI26_LN
# HNSCC26_P24_H05_S377_comb 1 1 0 T26 MEEI26_LN
# subtype
# Atypical
# Atypical
# Atypical
# Basal
# Atypical
# AtypicalVisualize HNSCC data using t-SNE
We plot the 2-D t-SNE embedding of these \(2,176\) malignant cells, which are colored by patient of origin and tumor stage (primary tumor, LN metastasis), and shaped by tumor molecular subtype. We set seed to make the t-SNE reproducible.
set.seed(100)
hnscc <- CreateSeuratObject(counts = t(Y), project = "HNSCC", meta.data = info)
hnscc <- FindVariableFeatures(hnscc, selection.method = "vst",
nfeatures = 5000)
all.genes <- rownames(hnscc)
hnscc <- ScaleData(hnscc, features = all.genes)
hnscc <- RunPCA(hnscc, features = VariableFeatures(object = hnscc),
npcs = 50, verbose = FALSE)
hnscc <- RunTSNE(hnscc, dims = 1:50)Due to the presence of strong inter-tumor heterogeneity, these cells demonstrate strong patient effects that are typical of cancer data; the major structure in the t-SNE visualization is the clustering of the cells by patient.
DimPlot(hnscc, label = TRUE, repel = TRUE, pt.size = 1, reduction = "tsne",
group.by = "subject", shape.by = "subtype", cols = subject_col) +
guides(shape = guide_legend(override.aes = list(size = 3)), ncol = 1) +
theme(text = element_text(size = 10)) +
scale_shape_manual(values = c(15,16,18))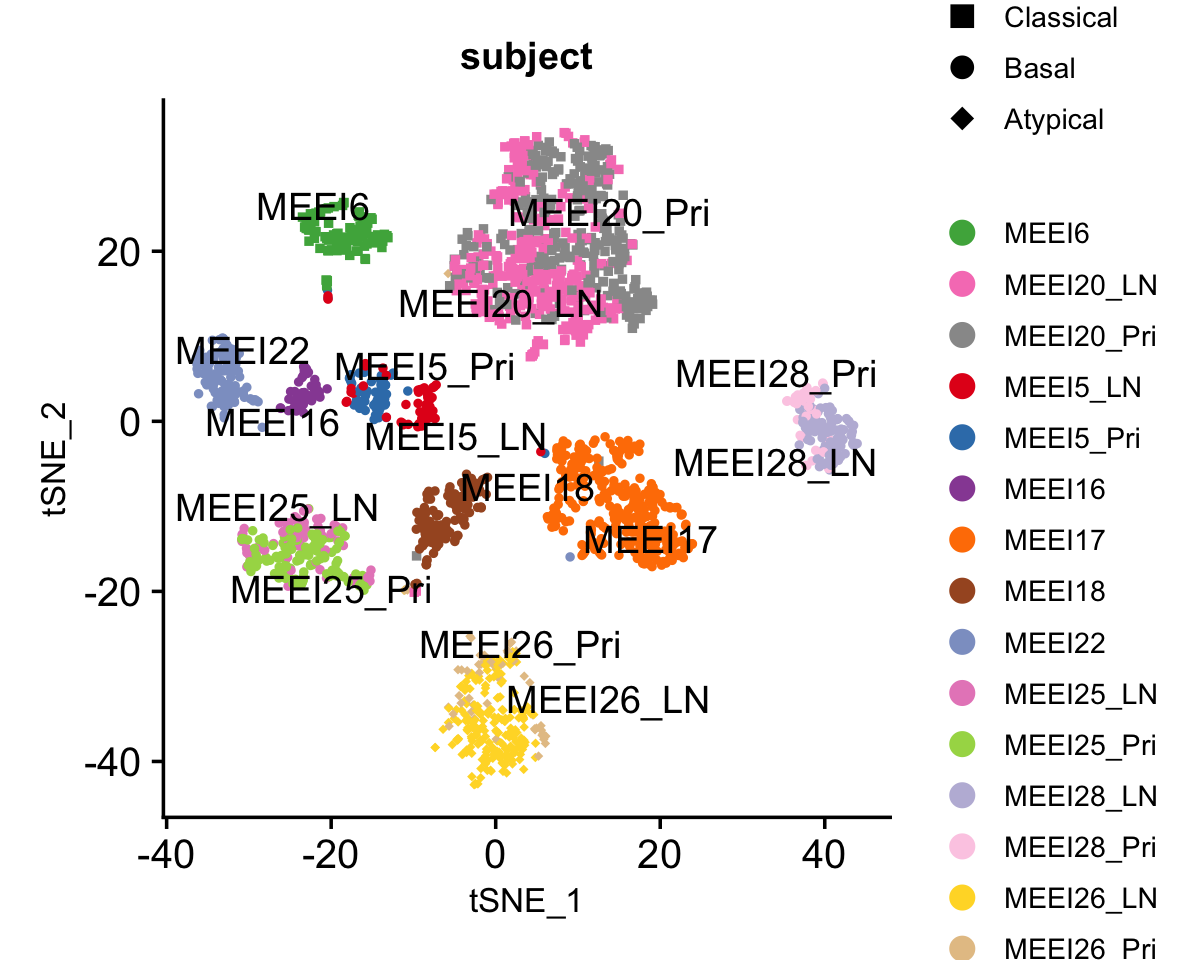
| Version | Author | Date |
|---|---|---|
| d40f7d0 | Peter Carbonetto | 2023-08-09 |
Apply GBCD to estimate GEP memberships and signatures
This is accomplished with a call to the custom function
flash_fit_cov_ebmf.
To fit GBCD, you need to specify Kmax, an upper bound of
the number of components \(K\), for
initialization; the number of GEPs returned by GBCD is close to but
often not equal to (and can be larger than) Kmax. Generally
speaking, a larger Kmax allows for identifying finer
structure in tumor transcriptional heterogeneity at the expense of
higher computational cost. A good choice of Kmax depends on
the complexity of the analyzed data (e.g., the number of patients and
studies contained), and is often unknown in advance. You are encouraged
to explore and compare the results for different values of
Kmax. After some initial exploration, we set
Kmax to 24.
You also need to specify a prior for GEP membership values. GBCD assigns a “generalized binary” (GB) prior independently to each entry of \(L\), \[l_{ik}\sim (1-\pi_k^l) \delta_0 + \pi_k^l \: N_{+} (\mu_k, \sigma_k^2),\] where the ratio \(\sigma_k/\mu_k\) is fixed at some pre-specified small value. In this analysis, we set \(\sigma_k/\mu_k = 0.04\) for all \(k\).
fit.gbcd <-
flash_fit_cov_ebnmf(Y = Y, Kmax = 24,
prior = flash_ebnm(prior_family = "generalized_binary",
scale = 0.04),
extrapolate = FALSE)Note that you can choose other nonnegative priors for GEP membership
values so long as they are defined in the ebnm package. For
example, you can chose a point-exponential prior by setting
prior = ebnm::ebnm_point_exponential.
The time to fit GBCD depends on the choice of Kmax and
the size of the data set being analyzed. It took us a few hours to fit
the GBCD model with Kmax = 24 to the HNSCC data set.
Since it takes a while to fit GBCD to the HNSCC dataset, we directly load in the saved output from the above call and show how to interpret the results.
load("../hnscc/hnscc_gbcd.RData")The flash_fit_cov_ebnmf output contains the membership
estimates, stored as an \(n \times K\)
matrix,
dim(fit.gbcd$L)
fit.gbcd$L[1:4,1:5]
# [1] 2176 29
# Baseline GEP1 GEP2 GEP3
# HN26_P14_D11_S239_comb 0.7404634 3.538229e-110 2.323954e-141 9.039494e-01
# HN26_P25_H09_S189_comb 0.6666176 5.623800e-137 9.582078e-135 7.786085e-01
# HN26_P14_H06_S282_comb 0.7976365 8.636394e-136 2.833297e-01 7.258564e-01
# HN25_P25_C04_S316_comb 0.4193556 6.158516e-137 5.124139e-01 4.286821e-135
# GEP4
# HN26_P14_D11_S239_comb 4.589753e-141
# HN26_P25_H09_S189_comb 9.840882e-136
# HN26_P14_H06_S282_comb 2.828108e-122
# HN25_P25_C04_S316_comb 1.527244e-135and posterior statistics for the LFC estimates, including the posterior means, stored as an \(m \times K\) matrix,
dim(fit.gbcd$F$lfc)
fit.gbcd$F$lfc[1:4,1:5]
# [1] 17113 29
# Baseline GEP1 GEP2 GEP3 GEP4
# C9orf152 0.0001609319 0.0002929911 0.000234652 -0.0004093085 0.0002814196
# ELMO2 2.0116827172 -0.0060056851 -0.601995065 0.0387999604 -0.0188075633
# PNMA1 1.6386413103 -0.0021806303 -1.244428917 0.0164347046 -0.0059650037
# MMP2 0.4807052706 -0.3115376229 1.673189435 -0.4256140576 -1.1229331251GEP membership estimates
We now examine at the entries of the L matrix giving
membership estimates of cell \(i\) in
GEP \(k\). Here we visually compare the
memberships to the patient labels and provided tumor subtype annotations
with a heatmap.
anno <- data.frame(subject = info$subject,
subtype = info$subtype)
rownames(anno) <- rownames(fit.gbcd$L)
anno_colors <- list(subject = subject_col,
subtype = subtype_col)
cols <- colorRampPalette(c("gray96","red"))(50)
brks <- seq(0,1,0.02)
rows <- order(anno$subject)
p <- pheatmap(fit.gbcd$L[rows, -1], cluster_rows = FALSE, cluster_cols = FALSE,
show_rownames = FALSE, annotation_row = anno,
annotation_colors = anno_colors, annotation_names_row = FALSE,
angle_col = 45, fontsize = 8, color = cols, breaks = brks,
main = "")
print(p) 
| Version | Author | Date |
|---|---|---|
| d40f7d0 | Peter Carbonetto | 2023-08-09 |
This heatmap shows the membership values of the n = 2,176 cells (the rows in the heatmap) and the 28 GEPs (the columns in the heatmap). (The membership values for the “baseline” GEP are not shown.) Cells are arranged top-to-bottom by tumor molecular subtype and patient of origin. We rescaled the membership values separately for each GEP so that the maximum membership for each GEP is always 1.
From this heatmap, we see that GEPs 1, 2 and 3 correspond closely to the molecular subtypes previously defined based on bulk RNA-seq data: GEP1 is largely active only in cells from the 2 classical patients, GEP2 is mainly active in cells from the 7 basal patients, and GEP3 is mainly active in cells from the 1 atypical patient. This demonstrates that GBCD can reconstruct the molecular subtype information from the single cell data alone.
Among other GEPs, some are active predominantly in an individual patient and can thus be interpreted as patient-specific GEPs. We interpret GEPs 4, 7, 9, 11, 25, 27 as “patient-specific GEPs”; the remaining GEPs are shared across multiple patients but are capturing something different than these previously defined molecular subtypes.
GEP signature estimates
The GEP signature estimates \(f_{jk}\) represent approximately the log-fold change (using t he base-2 logarithm) associated with membership in GEP \(k\). We take the approach commonly used in differential expression analysis and create a “volcano plot” to visualize the gene signature for a GEP. As an example, this is the volcano plot for GEP2:
k <- "GEP2"
pdat <- data.frame(gene = rownames(fit.gbcd$F$lfc),
lfc = fit.gbcd$F$lfc[,k],
z = abs(fit.gbcd$F$z_score[,k]),
lfsr = fit.gbcd$F$lfsr[,k],
stringsAsFactors = FALSE)
pdat <- transform(pdat,lfsr = cut(lfsr, c(-1,0.001,0.01,0.05,Inf)))
rows <- with(pdat, which(!(abs(lfc) > quantile(abs(lfc),0.999) | (z > 10))))
pdat[rows, "gene"] <- ""
ggplot(pdat, aes(x = lfc, y = z, color = lfsr, label = gene)) +
geom_point() +
geom_text_repel(color = "black", size = 2.3, segment.color = "black",
segment.size = 0.25, min.segment.length = 0,
max.overlaps = Inf, na.rm = TRUE) +
scale_color_manual(values = c("coral","orange","gold","deepskyblue")) +
labs(x = "log-fold change", y = "|posterior z-score|") +
theme_cowplot(font_size = 10)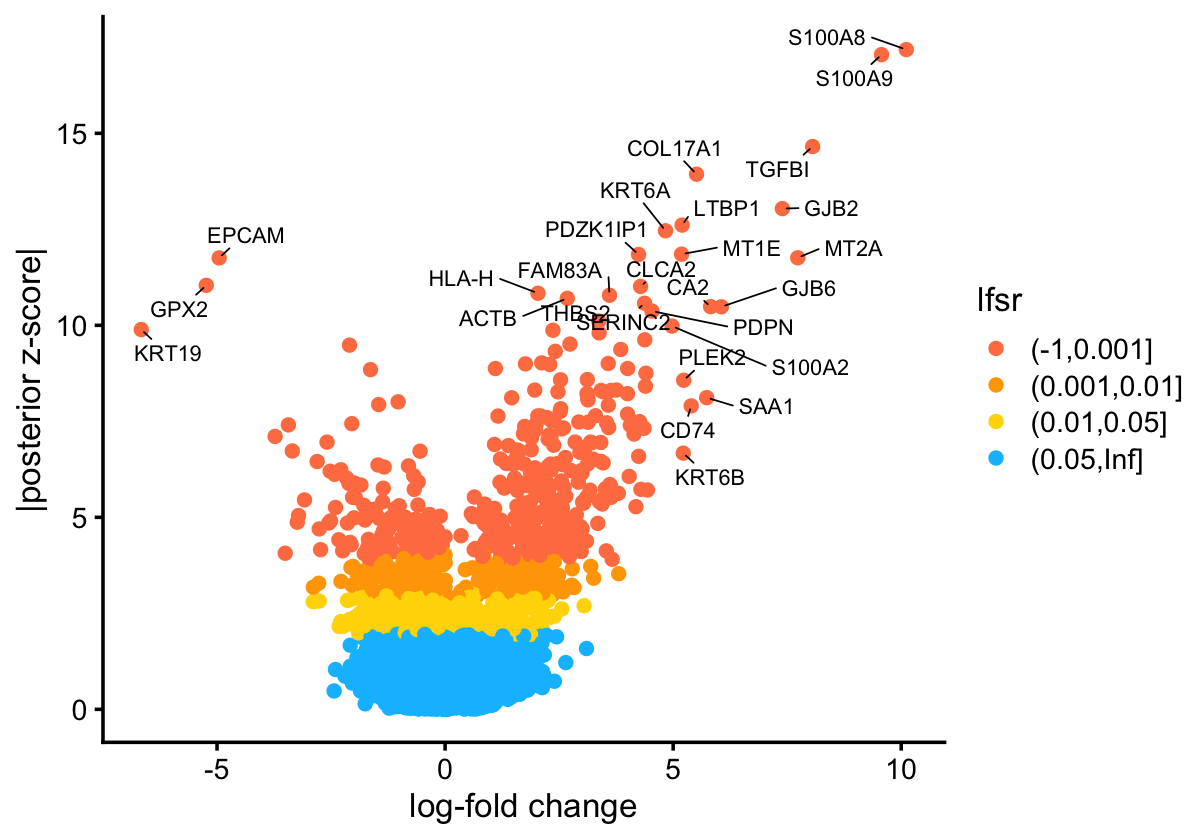
The significance measure here is not a p-value, but rather a local false sign rate (lfsr).
Session info
This is the version of R and the packages that were used to generate these results.
sessionInfo()
# R version 4.2.1 (2022-06-23)
# Platform: aarch64-apple-darwin20 (64-bit)
# Running under: macOS Monterey 12.4
#
# Matrix products: default
# BLAS: /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/lib/libRblas.0.dylib
# LAPACK: /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/lib/libRlapack.dylib
#
# locale:
# [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#
# attached base packages:
# [1] stats graphics grDevices utils datasets methods base
#
# other attached packages:
# [1] ashr_2.2-54 flashier_0.2.51 magrittr_2.0.3 ebnm_1.0-46
# [5] Matrix_1.4-1 sp_1.5-0 SeuratObject_4.1.0 Seurat_4.1.1
# [9] gridExtra_2.3 pheatmap_1.0.12 ggrepel_0.9.1 RColorBrewer_1.1-3
# [13] cowplot_1.1.1 ggplot2_3.4.2
#
# loaded via a namespace (and not attached):
# [1] workflowr_1.7.0 plyr_1.8.7 igraph_1.3.4
# [4] lazyeval_0.2.2 splines_4.2.1 listenv_0.8.0
# [7] scattermore_0.8 digest_0.6.29 invgamma_1.1
# [10] htmltools_0.5.3 SQUAREM_2021.1 fansi_1.0.3
# [13] tensor_1.5 cluster_2.1.3 ROCR_1.0-11
# [16] globals_0.15.1 matrixStats_0.62.0 spatstat.sparse_2.1-1
# [19] colorspace_2.0-3 xfun_0.31 dplyr_1.1.2
# [22] jsonlite_1.8.7 progressr_0.10.1 spatstat.data_2.2-0
# [25] survival_3.5-5 zoo_1.8-10 glue_1.6.2
# [28] polyclip_1.10-0 gtable_0.3.0 leiden_0.4.2
# [31] future.apply_1.9.0 abind_1.4-5 scales_1.2.0
# [34] DBI_1.1.3 spatstat.random_2.2-0 miniUI_0.1.1.1
# [37] Rcpp_1.0.9 viridisLite_0.4.0 xtable_1.8-4
# [40] reticulate_1.25 spatstat.core_2.4-4 truncnorm_1.0-8
# [43] htmlwidgets_1.5.4 httr_1.4.6 ellipsis_0.3.2
# [46] ica_1.0-3 pkgconfig_2.0.3 farver_2.1.1
# [49] sass_0.4.2 uwot_0.1.11 deldir_1.0-6
# [52] utf8_1.2.2 tidyselect_1.2.0 labeling_0.4.2
# [55] rlang_1.1.1 softImpute_1.4-1 reshape2_1.4.4
# [58] later_1.3.0 munsell_0.5.0 tools_4.2.1
# [61] cachem_1.0.6 cli_3.6.1 generics_0.1.3
# [64] ggridges_0.5.3 evaluate_0.15 stringr_1.5.0
# [67] fastmap_1.1.0 yaml_2.3.5 goftest_1.2-3
# [70] knitr_1.39 fs_1.5.2 fitdistrplus_1.1-8
# [73] purrr_1.0.1 RANN_2.6.1 pbapply_1.5-0
# [76] future_1.27.0 nlme_3.1-157 whisker_0.4
# [79] mime_0.12 compiler_4.2.1 rstudioapi_0.14
# [82] plotly_4.10.0 png_0.1-7 spatstat.utils_2.3-1
# [85] tibble_3.2.1 bslib_0.4.0 deconvolveR_1.2-1
# [88] stringi_1.7.8 highr_0.9 rgeos_0.5-9
# [91] lattice_0.20-45 vctrs_0.6.3 pillar_1.9.0
# [94] lifecycle_1.0.3 trust_0.1-8 spatstat.geom_2.4-0
# [97] lmtest_0.9-40 jquerylib_0.1.4 RcppAnnoy_0.0.19
# [100] data.table_1.14.2 irlba_2.3.5 httpuv_1.6.5
# [103] patchwork_1.1.2 R6_2.5.1 horseshoe_0.2.0
# [106] promises_1.2.0.1 KernSmooth_2.23-20 parallelly_1.32.1
# [109] codetools_0.2-18 MASS_7.3-57 rprojroot_2.0.3
# [112] withr_2.5.0 sctransform_0.3.3 mgcv_1.8-40
# [115] parallel_4.2.1 grid_4.2.1 rpart_4.1.16
# [118] tidyr_1.3.0 rmarkdown_2.14 Rtsne_0.16
# [121] git2r_0.31.0 mixsqp_0.3-43 shiny_1.7.2
sessionInfo()
# R version 4.2.1 (2022-06-23)
# Platform: aarch64-apple-darwin20 (64-bit)
# Running under: macOS Monterey 12.4
#
# Matrix products: default
# BLAS: /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/lib/libRblas.0.dylib
# LAPACK: /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/lib/libRlapack.dylib
#
# locale:
# [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#
# attached base packages:
# [1] stats graphics grDevices utils datasets methods base
#
# other attached packages:
# [1] ashr_2.2-54 flashier_0.2.51 magrittr_2.0.3 ebnm_1.0-46
# [5] Matrix_1.4-1 sp_1.5-0 SeuratObject_4.1.0 Seurat_4.1.1
# [9] gridExtra_2.3 pheatmap_1.0.12 ggrepel_0.9.1 RColorBrewer_1.1-3
# [13] cowplot_1.1.1 ggplot2_3.4.2
#
# loaded via a namespace (and not attached):
# [1] workflowr_1.7.0 plyr_1.8.7 igraph_1.3.4
# [4] lazyeval_0.2.2 splines_4.2.1 listenv_0.8.0
# [7] scattermore_0.8 digest_0.6.29 invgamma_1.1
# [10] htmltools_0.5.3 SQUAREM_2021.1 fansi_1.0.3
# [13] tensor_1.5 cluster_2.1.3 ROCR_1.0-11
# [16] globals_0.15.1 matrixStats_0.62.0 spatstat.sparse_2.1-1
# [19] colorspace_2.0-3 xfun_0.31 dplyr_1.1.2
# [22] jsonlite_1.8.7 progressr_0.10.1 spatstat.data_2.2-0
# [25] survival_3.5-5 zoo_1.8-10 glue_1.6.2
# [28] polyclip_1.10-0 gtable_0.3.0 leiden_0.4.2
# [31] future.apply_1.9.0 abind_1.4-5 scales_1.2.0
# [34] DBI_1.1.3 spatstat.random_2.2-0 miniUI_0.1.1.1
# [37] Rcpp_1.0.9 viridisLite_0.4.0 xtable_1.8-4
# [40] reticulate_1.25 spatstat.core_2.4-4 truncnorm_1.0-8
# [43] htmlwidgets_1.5.4 httr_1.4.6 ellipsis_0.3.2
# [46] ica_1.0-3 pkgconfig_2.0.3 farver_2.1.1
# [49] sass_0.4.2 uwot_0.1.11 deldir_1.0-6
# [52] utf8_1.2.2 tidyselect_1.2.0 labeling_0.4.2
# [55] rlang_1.1.1 softImpute_1.4-1 reshape2_1.4.4
# [58] later_1.3.0 munsell_0.5.0 tools_4.2.1
# [61] cachem_1.0.6 cli_3.6.1 generics_0.1.3
# [64] ggridges_0.5.3 evaluate_0.15 stringr_1.5.0
# [67] fastmap_1.1.0 yaml_2.3.5 goftest_1.2-3
# [70] knitr_1.39 fs_1.5.2 fitdistrplus_1.1-8
# [73] purrr_1.0.1 RANN_2.6.1 pbapply_1.5-0
# [76] future_1.27.0 nlme_3.1-157 whisker_0.4
# [79] mime_0.12 compiler_4.2.1 rstudioapi_0.14
# [82] plotly_4.10.0 png_0.1-7 spatstat.utils_2.3-1
# [85] tibble_3.2.1 bslib_0.4.0 deconvolveR_1.2-1
# [88] stringi_1.7.8 highr_0.9 rgeos_0.5-9
# [91] lattice_0.20-45 vctrs_0.6.3 pillar_1.9.0
# [94] lifecycle_1.0.3 trust_0.1-8 spatstat.geom_2.4-0
# [97] lmtest_0.9-40 jquerylib_0.1.4 RcppAnnoy_0.0.19
# [100] data.table_1.14.2 irlba_2.3.5 httpuv_1.6.5
# [103] patchwork_1.1.2 R6_2.5.1 horseshoe_0.2.0
# [106] promises_1.2.0.1 KernSmooth_2.23-20 parallelly_1.32.1
# [109] codetools_0.2-18 MASS_7.3-57 rprojroot_2.0.3
# [112] withr_2.5.0 sctransform_0.3.3 mgcv_1.8-40
# [115] parallel_4.2.1 grid_4.2.1 rpart_4.1.16
# [118] tidyr_1.3.0 rmarkdown_2.14 Rtsne_0.16
# [121] git2r_0.31.0 mixsqp_0.3-43 shiny_1.7.2